Understanding Model-Based and Model-Free Reinforcement Learning
http://Understanding Model-Based and Model-Free Reinforcement Learning
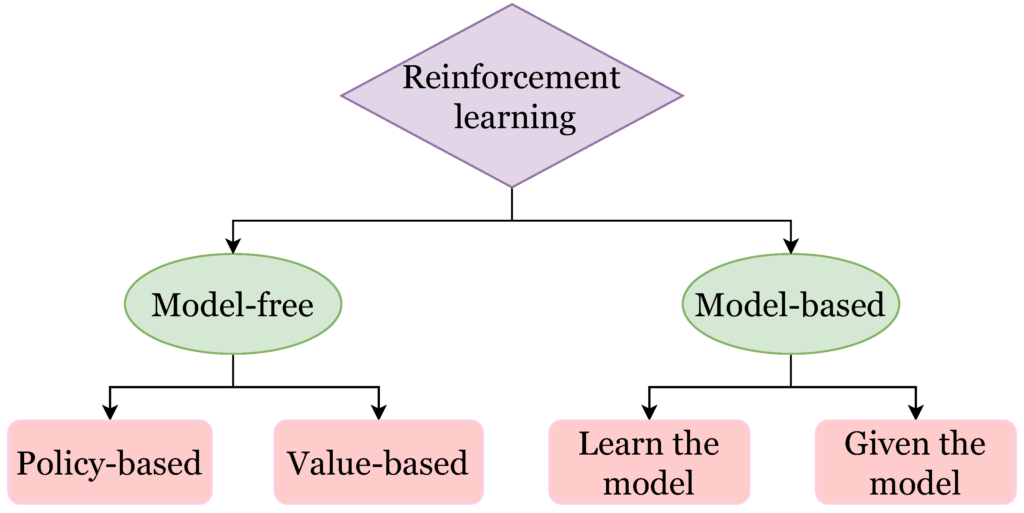
Reinforcement Learning (RL) is one of the most fascinating fields in machine learning, focusing on teaching agents to make sequences of decisions to maximize cumulative rewards. The two main approaches in RL are Model-Based and Model-Free Reinforcement Learning. These paradigms represent fundamentally different ways of addressing decision-making problems.
In this comprehensive guide, we will explore these two approaches, their features, key algorithms, examples, advantages, disadvantages, and real-world applications, along with detailed Python code snippets for each.
What is Reinforcement Learning?

Before diving into model-based and model-free approaches, let’s briefly revisit what RL entails. RL involves:
- An Agent: The learner or decision-maker.
- An Environment: Where the agent performs actions and receives feedback.
- States: The current situation of the agent in the environment.
- Actions: The choices available to the agent.
- Rewards: Feedback signals indicating the success of an action.
The agent learns to select actions that maximize the cumulative rewards over time.
What is Model-Based Reinforcement Learning?
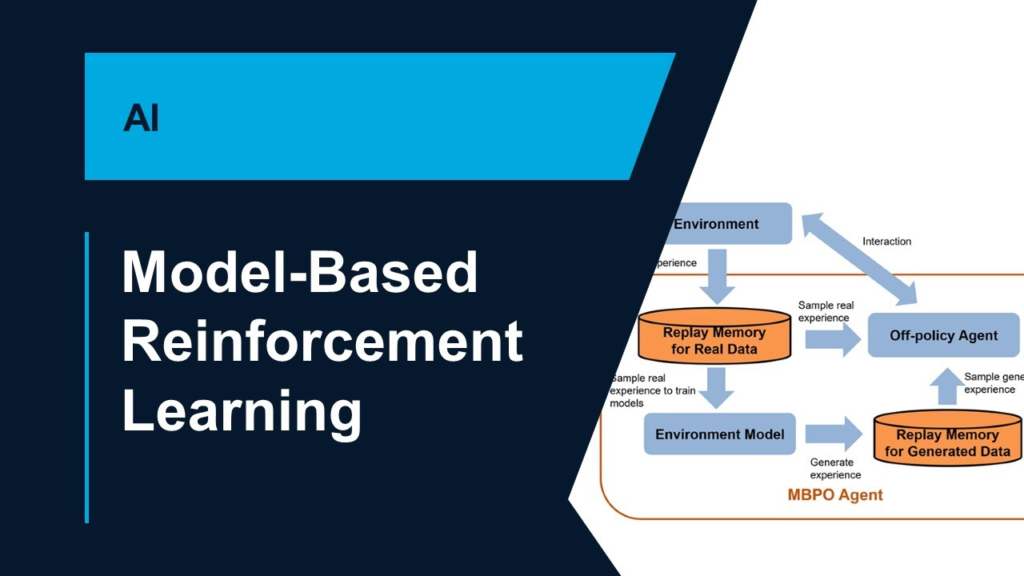
Model-based RL involves creating a model of the environment. The model predicts how the environment behaves in response to the agent’s actions. Once this model is available, the agent can use it to simulate outcomes and plan its future actions effectively.
Core Idea
The agent explicitly understands the dynamics of the environment through a function P(s′,r∣s,a)P(s’, r | s, a), which predicts:
- The probability of reaching a new state s′s’ given the current state ss and action aa.
- The reward rr associated with this transition.
How It Works
- Model Learning: Build the environment’s model through observations or assumptions.
- Planning: Use the model to simulate future trajectories and evaluate the expected reward of different strategies.
- Policy Improvement: Refine the policy based on simulated outcomes.
Examples of Model-Based Algorithms
- Dynamic Programming:
- Value Iteration: Iteratively calculate the value of each state until convergence.
- Policy Iteration: Alternates between policy evaluation and policy improvement.
- Monte Carlo Tree Search (MCTS):
- Used in games like chess and Go (e.g., AlphaZero).
- Combines simulation and search to find optimal strategies.
- Model Predictive Control (MPC):
- Often used in robotics.
- Plans a sequence of actions by solving optimization problems at each step.
Advantages of Model-Based RL
- Data Efficiency: By simulating the environment, fewer interactions with the actual environment are required.
- Long-Term Planning: Ideal for tasks that require strategic foresight.
Disadvantages of Model-Based RL
- Model Complexity: Building an accurate model for complex environments can be challenging.
- Error Propagation: Small inaccuracies in the model can lead to suboptimal or even incorrect decisions.
What is Model-Free Reinforcement Learning?
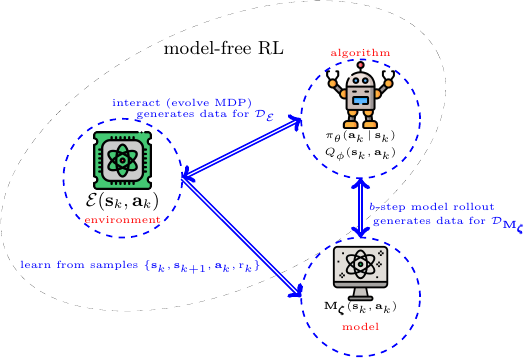
Model-free RL, in contrast, skips building a model of the environment. Instead, the agent learns directly from its interactions with the environment by optimizing a policy or value function.
Core Idea
The agent does not need to know the transition probabilities or rewards in advance. It relies entirely on trial-and-error learning.
How It Works
- Policy Optimization: Learn a policy π(a∣s)\pi(a | s) that maps states to actions to maximize rewards.
- Value Estimation: Learn a value function V(s)V(s) or action-value function Q(s,a)Q(s, a) to predict the long-term reward.
Examples of Model-Free Algorithms
- Value-Based Methods:
- Q-Learning: Estimates the Q-values for state-action pairs and selects actions greedily.
- Deep Q-Networks (DQN): Extends Q-learning using neural networks.
- Policy-Based Methods:
- REINFORCE: A Monte Carlo policy gradient method.
- Proximal Policy Optimization (PPO): Balances exploration and exploitation while optimizing the policy.
- Actor-Critic Methods:
- Combines value-based and policy-based approaches.
- Examples: Advantage Actor-Critic (A2C), Deep Deterministic Policy Gradient (DDPG).
Advantages of Model-Free RL
- Simpler: No need to model the environment.
- Generalizable: Can handle high-dimensional, unstructured environments.
Disadvantages of Model-Free RL
- Data-Hungry: Requires more interactions to learn effectively.
- Slower Convergence: May take longer to find an optimal policy.
Key Differences Between Model-Based and Model-Free RL
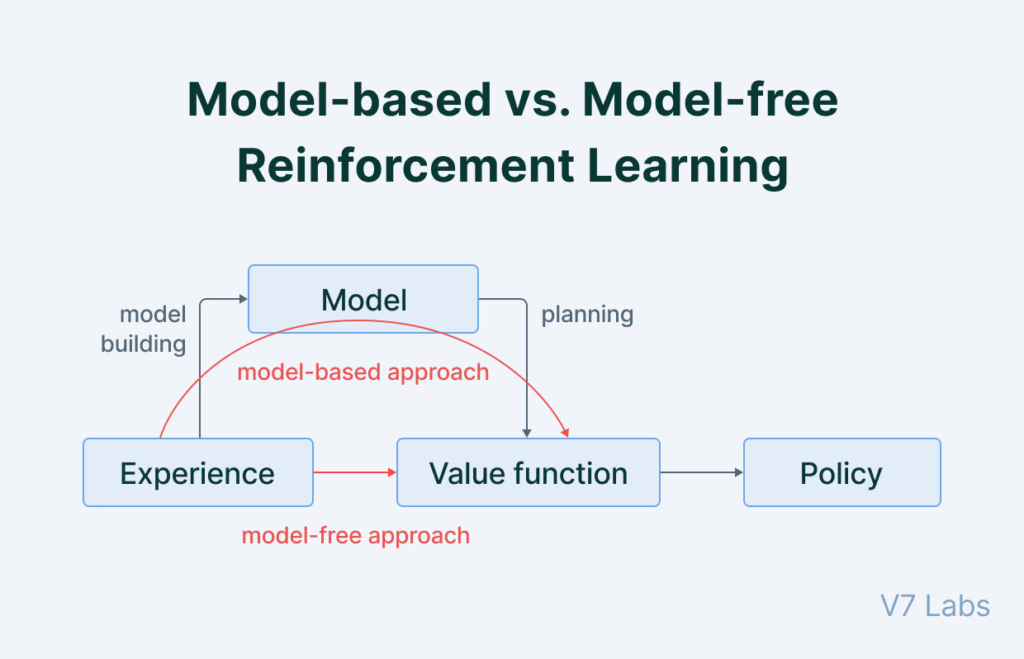
| Feature | Model-Based RL | Model-Free RL |
|---|---|---|
| Environment Model | Requires an explicit model | Does not require a model |
| Learning Efficiency | Faster (uses simulations) | Slower (trial-and-error) |
| Complexity | Higher (due to modeling) | Moderate |
| Scenarios | Structured environments | Unstructured environments |
| Algorithms | Dynamic Programming, AlphaZero | Q-Learning, PPO, DQN |
Real-World Applications
Model-Based RL Applications
- Robotics:
- Planning movements using MPC.
- Simulating environments to improve robot behavior.
- Games:
- AlphaZero’s dominance in chess and Go.
- Monte Carlo Tree Search with learned models.
- Healthcare:
- Predicting patient outcomes and planning optimal treatments.
Model-Free RL Applications
- Autonomous Vehicles:
- Learning to navigate complex environments without predefined models.
- Finance:
- Algorithmic trading through direct interaction with market data.
- Gaming:
- Deep Q-Networks in Atari games.
Code Examples
Model-Free RL: Q-Learning Implementation
Here’s an implementation of Q-Learning, a classic model-free algorithm:
import numpy as np
# Initialize Q-table
states = 5
actions = 2
q_table = np.zeros((states, actions))
# Parameters
learning_rate = 0.1
discount_factor = 0.9
epsilon = 0.1
episodes = 1000
# Training loop
for episode in range(episodes):
state = np.random.randint(0, states) # Random initial state
for step in range(100): # Limit steps per episode
if np.random.uniform(0, 1) < epsilon:
action = np.random.randint(0, actions) # Explore
else:
action = np.argmax(q_table[state, :]) # Exploit
# Simulate next state and reward
next_state = (state + action) % states
reward = 1 if next_state == states - 1 else -1
# Update Q-value
q_table[state, action] += learning_rate * (
reward + discount_factor * np.max(q_table[next_state, :]) - q_table[state, action]
)
state = next_state
if state == states - 1:
break
HTML Editor View:
<!DOCTYPE html>
<html>
<head>
<title>Q-Learning Implementation</title>
</head>
<body>
<pre>
import numpy as np
# Initialize Q-table
states = 5
actions = 2
q_table = np.zeros((states, actions))
# Parameters
learning_rate = 0.1
discount_factor = 0.9
epsilon = 0.1
episodes = 1000
# Training loop
for episode in range(episodes):
state = np.random.randint(0, states) # Random initial state
for step in range(100): # Limit steps per episode
if np.random.uniform(0, 1) < epsilon:
action = np.random.randint(0, actions) # Explore
else:
action = np.argmax(q_table[state, :]) # Exploit
# Simulate next state and reward
next_state = (state + action) % states
reward = 1 if next_state == states - 1 else -1
# Update Q-value
q_table[state, action] += learning_rate * (
reward + discount_factor * np.max(q_table[next_state, :]) - q_table[state, action]
)
state = next_state
if state == states - 1:
break
</pre>
</body>
</html>
Conclusion
Model-based and model-free RL serve different purposes and are suitable for distinct scenarios. While model-based RL shines in environments where a model can be constructed or learned efficiently, model-free RL excels in complex, high-dimensional environments where modeling is infeasible.
Key Takeaways:
- Model-Based RL: Requires fewer environment interactions but relies heavily on the accuracy of the model.
- Model-Free RL: Simpler and more versatile but often slower to converge.
By understanding these approaches and their respective algorithms, you can choose the best RL strategy for your specific problem. Whether you’re training a robot, optimizing