comprehensiveb guide to In-Memory Computing for Big Data: Transforming Analytics with Speed and Efficiency 2024

In today’s data-driven landscape, businesses face the challenge of processing vast amounts of information in real-time. Traditional storage systems, such as disk-based databases, often struggle to meet the speed and latency demands of modern applications. In-Memory Computing (IMC) emerges as a revolutionary approach, leveraging RAM for faster data storage and processing.
This blog explores in-memory computing, its benefits, applications, and how it accelerates Big Data analytics.
What is In-Memory Computing?
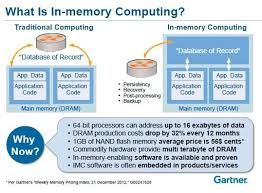
In-Memory Computing refers to the practice of storing and processing data directly in a system’s RAM (Random Access Memory), bypassing the slower disk-based storage systems. By distributing data across RAM clusters in a network, IMC enables high-speed computation and significantly reduces latency.
Key Features:
- RAM Storage:
- Stores data in primary memory (RAM), which is 5,000 times faster than traditional spinning disks.
- Parallel Processing:
- Distributes computational tasks across multiple nodes in a cluster.
- Low-Latency Processing:
- Ideal for real-time and iterative computations.
Hadoop vs. In-Memory Computing
Apache Hadoop has revolutionized Big Data processing, offering scalable storage and processing for batch applications. However, its reliance on persistent disk storage poses limitations for low-latency applications, such as:
- Iterative computations (e.g., machine learning).
- Real-time analytics (e.g., fraud detection).
- Graph algorithms.
In contrast, IMC addresses these issues by caching datasets in memory, enabling faster processing and real-time capabilities.
Advantages of In-Memory Computing

- Speed:
- By storing data in RAM, IMC accelerates data processing, enabling real-time analytics.
- Scalability:
- Distributed architecture supports seamless scaling as data volumes grow.
- Flexibility:
- Handles both structured (relational databases) and unstructured (NoSQL databases) data.
- Cost-Effectiveness:
- Decreasing RAM prices make IMC an affordable solution for Big Data processing.
Apache Spark: The Power of In-Memory Computing
Apache Spark is a leading framework for in-memory Big Data processing. It provides a general programming model that simplifies complex computations while leveraging RAM for low-latency processing.
Core Features of Spark:
- In-Memory Caching:
- Caches datasets in memory for subsequent computations, avoiding expensive disk I/O operations.
- Support for Iterative Algorithms:
- Shares data across iterations, making it ideal for machine learning and graph analytics.
- Stream and Batch Processing:
- Handles real-time streaming and batch workloads efficiently.
Use Cases:
- Machine Learning:
- Speeds up iterative training processes by caching datasets.
- Real-Time Analytics:
- Processes streaming data for fraud detection or recommendation engines.
- Complex Queries:
- Executes joins, group-bys, and aggregations at memory speeds.
Applications of In-Memory Computing

- E-Commerce:
- Use Case: Real-time product recommendations based on browsing history.
- Impact: Enhanced customer experience and increased sales.
- Finance:
- Use Case: Fraud detection by analyzing transaction patterns in real-time.
- Impact: Reduced financial losses and improved security.
- Healthcare:
- Use Case: Analyzing patient records for early disease detection.
- Impact: Better diagnostics and personalized treatment.
- Social Media:
- Use Case: Real-time sentiment analysis of trending topics.
- Impact: Improved audience engagement and brand reputation management.
Challenges of In-Memory Computing
- Cost:
- While RAM prices have decreased, the upfront cost of setting up an in-memory cluster can still be significant.
- Data Volume:
- Handling petabyte-scale datasets in memory requires robust cluster management and partitioning strategies.
- Complexity:
- Requires expertise in distributed computing frameworks like Apache Spark.
Best Practices for Implementing In-Memory Computing
- Optimize Data Caching:
- Cache frequently used datasets to reduce redundant computations.
df.cache() - Partition Data Efficiently:
- Distribute data across nodes to balance workloads and avoid bottlenecks.
- Monitor System Resources:
- Use monitoring tools to track memory usage and optimize cluster performance.
- Leverage Frameworks like Apache Spark:
- Simplify implementation with Spark’s built-in capabilities for in-memory processing.
Future of In-Memory Computing
- AI Integration:
- Combining in-memory computing with AI frameworks for faster model training and real-time predictions.
- Edge Computing:
- Extending in-memory capabilities to edge devices for localized, low-latency processing.
- Cloud-Native Solutions:
- Adoption of serverless architectures for cost-efficient and scalable deployments.
Conclusion
In-memory computing has redefined the boundaries of Big Data analytics, enabling organizations to process data faster, reduce latency, and deliver real-time insights. With frameworks like Apache Spark, businesses can unlock the full potential of their data, driving innovation and competitive advantage.
Are you ready to accelerate your analytics with in-memory computing? Start exploring today and experience the speed of real-time processing!