comprehensive guide to Data Augmentation: Enhancing Machine Learning Performance with More Data 2024
In the world of machine learning, data is king. Models thrive on diverse, high-quality datasets, but collecting and curating these datasets can be expensive, time-consuming, and sometimes impossible due to privacy concerns. Data augmentation offers a powerful solution by artificially expanding existing datasets, making models more robust and reliable.
This blog explores the concept of data augmentation, its types, and how it enhances performance across domains like computer vision and natural language processing (NLP).
What is Data Augmentation?

Data augmentation refers to a family of techniques used to artificially increase the size and diversity of training datasets. Traditionally employed for tasks with limited data, such as medical imaging, data augmentation is now a standard practice even in data-rich domains due to its ability to:
- Improve model robustness against noise and adversarial attacks.
- Enhance generalization.
- Boost performance on unseen data.
Applications:
- Computer Vision:
- Transformations like rotation, flipping, and cropping.
- Natural Language Processing (NLP):
- Synonym replacement and sentence paraphrasing.
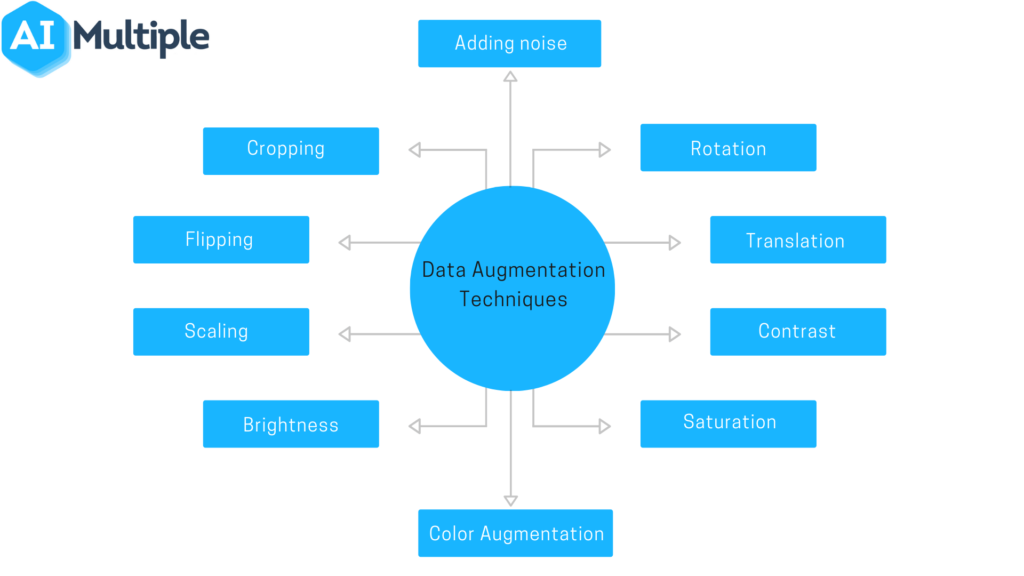
Types of Data Augmentation
Data augmentation techniques can be broadly categorized into three types:
1. Simple Label-Preserving Transformations
These techniques modify data without altering the underlying label.
Computer Vision:
- Common transformations include:
- Cropping
- Flipping
- Rotating
- Erasing parts of images
NLP:
- Replace words with synonyms or embeddings close in the vector space.
- Example:
- Original sentence: “The weather is pleasant.”
- Augmented sentence: “The climate is nice.”
Benefits:
- Quick and computationally inexpensive.
- Compatible with most ML frameworks like PyTorch and Keras.
2. Perturbation
Perturbation introduces noise to the data to make models more robust.
Computer Vision:
- Adds random noise to images to simulate adversarial attacks.
- Example:
- Small pixel alterations that cause misclassification.
Adversarial Augmentation:
- Generates noisy samples to improve the model’s decision boundary.
- Example Algorithm: DeepFool, which finds the minimal noise required to cause a high-confidence misclassification.
NLP:
- Introduces minor word or sentence-level perturbations to assess model robustness.
- Example:
- Misspellings or random word insertions.
3. Data Synthesis
Data synthesis involves generating entirely new samples using templates or neural networks.
NLP:
- Templates like:
- “Find me a [CUISINE] restaurant within [NUMBER] miles of [LOCATION].”
- Fill variables like CUISINE (Italian, Chinese), NUMBER (5, 10), and LOCATION (office, home) to create thousands of training examples.
Computer Vision:
- Techniques like Mixup, where two examples are combined to create a new one:
- From an image labeled DOG (0) and another labeled CAT (1), generate an interpolated image labeled as a weighted mix (e.g., 0.6 DOG and 0.4 CAT).
Why Use Data Augmentation?

- Improve Generalization:
- Reduces overfitting by diversifying the training set.
- Increase Robustness:
- Prepares models to handle noisy or adversarial data.
- Handle Class Imbalance:
- Augments minority classes in imbalanced datasets.
- Reduce Costs:
- Decreases reliance on expensive and time-consuming data collection.
Tools and Frameworks for Data Augmentation
- Computer Vision:
- PyTorch: Built-in transformations in
torchvision.transforms. - Keras:
ImageDataGeneratorfor real-time augmentation during training.
- PyTorch: Built-in transformations in
- NLP:
- Libraries like TextBlob and NLTK for synonym replacement.
- Custom scripts leveraging word embeddings like Word2Vec or GloVe.
Challenges and Limitations
- Quality Control:
- Poorly designed augmentation can introduce irrelevant patterns.
- Computational Overhead:
- Real-time augmentation may slow down training.
- Task-Specific Effectiveness:
- Not all augmentation techniques work across all tasks.
Future of Data Augmentation
- Neural Augmentation:
- Using GANs (Generative Adversarial Networks) to synthesize realistic data samples.
- Automated Augmentation:
- AutoML techniques for selecting the best augmentation strategies.
- Domain-Specific Innovations:
- Tailored augmentation for industries like healthcare and autonomous driving.
Conclusion
Data augmentation is a transformative approach that enhances machine learning models by expanding and diversifying datasets. By leveraging techniques like simple transformations, perturbations, and data synthesis, practitioners can build robust, generalizable models with fewer resources. As tools and techniques evolve, data augmentation will continue to play a pivotal role in advancing AI capabilities.
Ready to strengthen your models with data augmentation? Start exploring its endless possibilities today!