comprehensive guide of Data Observability: Ensuring Data Reliability in Modern Systems 2024

With the rise of big data, AI, and analytics, organizations rely on data-driven decision-making more than ever. However, unreliable data can erode trust, waste resources, and lead to flawed insights. This is where data observability comes into play.
Data Observability is the ability to monitor, diagnose, and ensure the health of data across pipelines and storage systems. It extends DevOps-style observability to the modern data stack, allowing teams to detect data anomalies, schema changes, and data quality issues before they impact business decisions.
This blog explores: ✅ What is Data Observability?
✅ The Five Pillars of Data Observability
✅ Why Data Observability Matters
✅ Best Practices for Building a Scalable Data Observability Framework
✅ The Future of Data Observability
What is Data Observability?
Data Observability is the practice of proactively monitoring, detecting, and resolving data issues to ensure reliability, trust, and quality across the entire data pipeline.
Unlike traditional data monitoring, which focuses on performance metrics (e.g., query latency, pipeline failures), data observability provides deeper insights into why data breaks, how it impacts systems, and where issues originate.
✅ Why is it Important?
- Prevents Data Downtime – Avoid periods when data is missing, incorrect, or unreliable.
- Ensures Trust in Analytics & AI Models – Bad data leads to flawed ML predictions and business insights.
- Improves Data Engineering Efficiency – Engineers spend less time firefighting broken pipelines.
- Enhances Governance & Compliance – Detect schema changes, unauthorized access, and security risks.
📌 Example:
A financial firm using AI-powered fraud detection must ensure its transaction data is accurate. A data observability system monitors real-time transaction logs for unexpected patterns, missing values, or schema mismatches, alerting engineers before incorrect data affects fraud predictions.
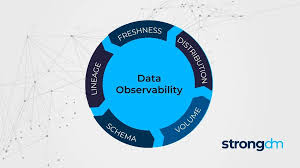
The Five Pillars of Data Observability

A comprehensive data observability strategy relies on five key components to ensure reliability.
1. Freshness (How Up-to-Date is Your Data?)
🚀 Objective: Ensure data arrives on time and is not stale or outdated.
📊 Key Metrics:
- Time since last data update
- Data ingestion frequency
- Late/missing records
📌 Example:
A real-time stock trading platform requires the latest market prices. If a data observability tool detects that price updates are delayed, it triggers alerts to prevent traders from acting on outdated data.
2. Data Quality (Is Your Data Trustworthy?)
🚀 Objective: Detect missing, duplicate, or incorrect data points.
📊 Key Metrics:
- Null values, duplicate records, outliers
- Expected vs. actual data distributions
- Anomalous trends in key datasets
📌 Example:
A healthcare analytics system analyzing patient records must ensure data fields (e.g., heart rate, blood pressure) contain valid values. Data observability tools detect missing values or incorrect units (e.g., Fahrenheit vs. Celsius) before doctors rely on faulty data.
3. Data Volume (Is Your Data Complete?)
🚀 Objective: Monitor data ingestion rates and detect unexpected drops or spikes.
📊 Key Metrics:
- Number of records per batch
- Data size changes
- Missing partitions in databases
📌 Example:
A marketing analytics dashboard aggregates daily ad campaign data. If a data observability system notices a sudden drop in impressions or revenue data, it alerts engineers to investigate missing data from ad platforms.
4. Schema Changes (Has Your Data Structure Changed?)
🚀 Objective: Track table structure modifications that might break pipelines or reports.
📊 Key Metrics:
- New/removed columns
- Data type changes
- Schema mismatches between upstream and downstream systems
📌 Example:
An e-commerce analytics team relies on an orders table. If a column (e.g., ‘customer_id’) is removed, dashboards and reporting tools may fail. Observability ensures teams detect schema changes before they cause failures.
5. Data Lineage (Where is Your Data Coming From & Going?)
🚀 Objective: Understand how data flows across systems to quickly identify sources of errors.
📊 Key Metrics:
- Upstream/downstream dependencies
- Data transformation logs
- Access control & data governance tracking
📌 Example:
A global retail chain tracks sales data from point-of-sale (POS) systems to business intelligence dashboards. Data lineage tools identify broken connections between upstream and downstream pipelines, ensuring reports always reflect accurate sales numbers.
Why Data Observability Matters

For data engineers and developers, data downtime is a costly issue. When data is incomplete, incorrect, or delayed, it wastes engineering time and erodes business trust.
Key Benefits of Data Observability: ✅ Prevents Data Pipeline Failures
✅ Boosts AI/ML Model Performance
✅ Reduces Time Spent Debugging Data Issues
✅ Improves Regulatory Compliance & Data Security
Best Practices for Implementing Data Observability
1. Automate Data Monitoring & Alerts
🔹 Use real-time monitoring tools like Monte Carlo or Databand.
🔹 Set up alerts for missing, duplicated, or delayed records.
2. Implement Data Lineage Tracking
🔹 Visualize data dependencies across ETL pipelines.
🔹 Identify how schema changes impact downstream analytics.
3. Establish Data Quality SLAs (Service Level Agreements)
🔹 Define acceptable thresholds for data completeness and accuracy.
🔹 Use machine learning-based anomaly detection for real-time issue tracking.
4. Use Machine Learning to Detect Data Drift
🔹 Monitor changes in feature distributions affecting ML models.
🔹 Set up automatic retraining pipelines for adapting to data drift.
5. Integrate Observability into DataOps & MLOps
🔹 Ensure data reliability at every stage of the data pipeline.
🔹 Use CI/CD workflows for testing data quality before production deployments.
Top Data Observability Tools
| Tool | Best For | Features |
|---|---|---|
| Monte Carlo | End-to-end data observability | Data freshness, volume monitoring |
| Evidently AI | ML-specific data monitoring | Detects feature drift, model drift |
| Databand | Data pipeline monitoring | Alerts for missing data & delays |
| Great Expectations | Data quality validation | Schema validation, missing values detection |
| Apache Atlas | Data lineage tracking | Metadata management, governance |
Future of Data Observability
🚀 1. AI-Powered Anomaly Detection – Predicting data issues before they occur.
🌍 2. Observability for Real-Time Streaming Data – Monitoring Kafka, Flink, and Spark pipelines.
🔄 3. Self-Healing Data Pipelines – Auto-repairing data ingestion failures.
📜 4. Regulatory Compliance & Governance – Ensuring GDPR, HIPAA, and AI Act compliance.
Final Thoughts
Data Observability is no longer optional—it’s an essential part of modern data engineering. By implementing real-time monitoring, lineage tracking, and data validation, organizations can ensure reliable data pipelines, boost AI accuracy, and prevent business disruptions.
📌 Ready to ensure your data is always reliable? Start by integrating observability tools today! 🚀