A Comprehensive Guide to Apache Kafka: Messaging Systems and Architecture 2024
Apache Kafka is a distributed event streaming platform designed for high-throughput, fault-tolerant, and scalable real-time data streaming. It acts as a messaging system that allows applications to communicate by producing and consuming messages efficiently.
In this guide, we will explore: ✅ Kafka messaging system types
✅ Kafka architecture and components
✅ Producers, brokers, and consumers
✅ ZooKeeper and cluster management
✅ Kafka workflow: Message flow from producer to consumer
1. Understanding Messaging Systems in Kafka
Kafka provides a robust messaging system that ensures reliable data transfer between applications.
A. What is a Messaging System?
A messaging system allows applications to exchange data without being directly connected. This ensures:
- Asynchronous communication (real-time or batch processing).
- Fault tolerance (messages are stored and retrieved later).
- Scalability (can handle large amounts of data).
B. Types of Messaging Systems
Kafka supports two main messaging models:
| Type | How it Works |
|---|---|
| Point-to-Point | Messages are stored in a queue. Only one consumer receives each message. |
| Pub-Sub (Publish-Subscribe) | Messages are stored in a topic. Multiple consumers can read the same message. |
✅ Kafka follows a distributed pub-sub model, making it highly scalable and fault-tolerant.
2. Kafka Architecture: Distributed and Scalable
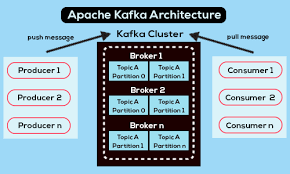
Kafka’s architecture is built for high throughput and reliability.
A. Key Components of Kafka
| Component | Role |
|---|---|
| Producers | Send messages to Kafka topics. |
| Brokers | Store messages and distribute them across consumers. |
| Consumers | Read messages from topics. |
| Topics | Logical categories to organize messages. |
| Partitions | Splits topics into multiple segments for scalability. |
| ZooKeeper | Manages broker metadata and leader election. |
B. Kafka Topics and Partitions
- A topic is a named category where producers send messages.
- A partition is a subset of a topic.
- Messages are stored in partitions in sequential order.
🔹 Example: Topic with 3 Partitions
mathematicaCopyEditTopic: "Orders"
Partition 1 → Messages 1, 2, 3
Partition 2 → Messages 4, 5, 6
Partition 3 → Messages 7, 8, 9
✅ Why Partitions?
- Allows parallel processing across consumers.
- Enables Kafka to scale horizontally by distributing partitions across multiple brokers.
3. Kafka Brokers: The Heart of the System
A Kafka broker is a server that stores messages and serves client requests.
✅ Brokers handle message storage, replication, and delivery.
| Broker Type | Role |
|---|---|
| Leader | Handles all reads and writes for a partition. |
| Follower | Replicates data from the leader. If the leader fails, a follower is promoted. |
🔹 Example: Cluster with 3 Brokers
mathematicaCopyEditBroker 1 → Leader for Partition 1, Follower for Partition 2
Broker 2 → Leader for Partition 2, Follower for Partition 3
Broker 3 → Leader for Partition 3, Follower for Partition 1
✅ Kafka ensures high availability by replicating data across brokers.
4. Kafka Producers: Sending Data to Topics

A Kafka Producer is responsible for:
- Publishing messages to Kafka topics.
- Choosing partitions for message distribution.
- Ensuring reliability using acknowledgments.
Producer Message Flow
1️⃣ Producer sends a message → Assigned to a topic.
2️⃣ Kafka broker stores the message in a partition.
3️⃣ Leader acknowledges the message → Ensures safe storage.
4️⃣ Message replication → Followers copy the data.
🔹 Example Code for a Kafka Producer in Python
pythonCopyEditfrom confluent_kafka import Producer
import json
config = {'bootstrap.servers': 'localhost:9092'}
producer = Producer(config)
message = {"order_id": 101, "product": "Laptop"}
producer.produce("orders", key="101", value=json.dumps(message))
producer.flush()
✅ Ensures reliable delivery of messages to Kafka.
5. Kafka Consumers: Reading Data from Topics
A Kafka Consumer is responsible for:
- Subscribing to topics.
- Reading messages from partitions.
- Tracking message offsets to prevent duplicates.
Consumer Message Flow
1️⃣ Consumer subscribes to a topic.
2️⃣ Kafka assigns partitions to consumers (if in a group).
3️⃣ Consumer reads messages and processes them.
4️⃣ Consumer acknowledges the offset (commit message).
🔹 Example Code for a Kafka Consumer in Python
pythonCopyEditfrom confluent_kafka import Consumer
config = {
'bootstrap.servers': 'localhost:9092',
'group.id': 'consumer_group_1',
'auto.offset.reset': 'earliest'
}
consumer = Consumer(config)
consumer.subscribe(['orders'])
while True:
msg = consumer.poll(timeout=1.0)
if msg:
print(f"Received: {msg.value().decode('utf-8')}")
✅ Consumers ensure efficient message processing by tracking offsets.
6. ZooKeeper: Managing Kafka Clusters
Kafka relies on ZooKeeper for:
- Leader election (deciding which broker controls a partition).
- Metadata storage (list of brokers and topics).
- Broker failure detection.
✅ Without ZooKeeper, Kafka cannot manage brokers efficiently.
7. Kafka Workflow: End-to-End Message Flow
How does Kafka handle messages from producer to consumer?
1️⃣ Producer sends data → Kafka broker stores it in a topic partition.
2️⃣ Broker acknowledges the producer (ensures delivery).
3️⃣ Consumer subscribes to the topic.
4️⃣ Consumer reads messages from the assigned partition.
5️⃣ Consumer acknowledges the offset to mark messages as read.
✅ Kafka ensures fault tolerance and at-least-once message delivery.
8. Benefits of Apache Kafka
| Feature | Advantage |
|---|---|
| Scalability | Easily scales by adding brokers. |
| Durability | Messages are persisted to disk and replicated. |
| Fault Tolerance | Handles broker failures automatically. |
| Performance | High throughput for real-time data processing. |
| Integration | Works with Hadoop, Spark, and Flink. |
🔹 Kafka is widely used for big data, microservices, and event-driven architectures.
9. Best Practices for Kafka
✅ Use replication to prevent data loss.
✅ Tune partitioning strategy for better parallelism.
✅ Monitor brokers and consumers using Kafka UI tools.
✅ Configure offsets correctly to prevent duplicate messages.
✅ Optimize compression (gzip, snappy) to save bandwidth.
10. Final Thoughts
Apache Kafka is one of the most powerful event-streaming platforms, enabling real-time data movement at scale. Whether you’re building log processing systems, recommendation engines, or real-time analytics, Kafka provides the reliability, performance, and scalability you need.
💡 How are you using Kafka in your projects? Let us know in the comments! 🚀