The Complete Machine Learning Lifecycle: Phases, Best Practices, and Tools 2024
Machine learning (ML) is a cyclical and iterative process that involves multiple stages, from defining business goals to model deployment and monitoring. A well-structured ML lifecycle ensures scalability, performance, and continuous learning while minimizing risks and biases.
This guide covers: ✅ The complete ML lifecycle and its phases
✅ Key methodologies and tools used at each stage
✅ Challenges in ML development and solutions
✅ Best practices for deploying and monitoring ML models
1. Understanding the Machine Learning Lifecycle
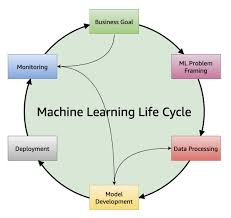
The ML lifecycle is a structured process that ensures an ML project is well-organized, repeatable, and scalable. It consists of the following key phases:
| Phase | Purpose |
|---|---|
| Business Goal Identification | Define the business problem and success metrics |
| ML Problem Framing | Translate the problem into an ML problem |
| Data Processing | Collect, clean, and prepare data |
| Model Development | Train, tune, and evaluate ML models |
| Model Deployment | Serve ML models for inference and predictions |
| Model Monitoring | Continuously track model performance and retrain |
🚀 Example:
A banking system may use ML to predict fraudulent transactions, requiring a structured ML lifecycle to ensure data quality, model accuracy, and real-time inference.
2. Phase 1: Business Goal Identification
Before building an ML model, it is crucial to define the problem and expected business impact.
Steps in Business Goal Identification
✅ Understand Business Requirements – Identify the core business problem.
✅ Review ML Feasibility – Check if ML is the right solution.
✅ Evaluate Data Availability – Assess if sufficient data exists.
✅ Estimate Costs – Consider data acquisition, training, and model inference costs.
✅ Set Key Performance Metrics – Define accuracy, recall, or business KPIs.
🚀 Example:
A retail company wants to increase sales through personalized product recommendations. The success metric is increased purchase conversion rates.
3. Phase 2: ML Problem Framing
Once the business problem is defined, the next step is to frame it as an ML problem.
Key Questions in ML Problem Framing
✅ What is the target variable? (e.g., churn rate, fraud risk)
✅ What type of ML model is needed? (classification, regression, clustering)
✅ What performance metrics should be optimized? (accuracy, F1-score, RMSE)
✅ Do we have enough labeled data?
🚀 Example:
A loan provider wants to predict loan defaults.
- Target variable: Loan repayment (yes/no).
- Model Type: Binary classification.
- Performance Metric: Precision and recall.
4. Phase 3: Data Processing
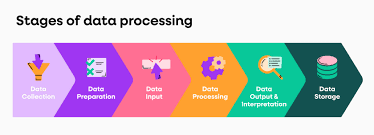
Data is the backbone of ML models, and high-quality data leads to better predictions.
Data Processing Steps
✅ Data Collection – Gather data from APIs, logs, IoT devices, or databases.
✅ Data Cleaning – Handle missing values, outliers, and duplicates.
✅ Feature Engineering – Create meaningful input variables.
✅ Data Splitting – Partition data into training, validation, and test sets.
Common Tools for Data Processing
| Task | Tools |
|---|---|
| ETL & Data Collection | Apache Kafka, AWS Glue, Google Cloud Dataflow |
| Data Cleaning | Pandas, PySpark, Great Expectations |
| Feature Engineering | Scikit-learn, Feature Store (Feast) |
🚀 Example:
A healthcare startup builds a disease prediction model by processing patient medical records.
5. Phase 4: Model Development
Once data is prepared, the next step is model training, hyperparameter tuning, and evaluation.
Steps in Model Development
✅ Feature Selection – Choose the most relevant features.
✅ Algorithm Selection – Test multiple models (Random Forest, XGBoost, CNNs).
✅ Hyperparameter Tuning – Optimize parameters for best performance.
✅ Model Evaluation – Use accuracy, precision, recall, or RMSE to assess performance.
Common Tools for Model Development
| Task | Tools |
|---|---|
| Model Training | TensorFlow, PyTorch, Scikit-learn |
| Hyperparameter Tuning | Optuna, Ray Tune |
| Model Evaluation | MLflow, Weights & Biases |
🚀 Example:
A credit card company builds an anomaly detection model for fraud detection by training XGBoost on transaction data.
6. Phase 5: Model Deployment
After training and evaluating a model, it must be deployed into a production environment.
Deployment Strategies
✅ Blue-Green Deployment – Use two production environments for smooth transitions.
✅ Canary Deployment – Deploy to a small subset of users first.
✅ A/B Testing – Compare two models in production.
✅ Shadow Deployment – Run new and old models in parallel for evaluation.
Common Tools for Model Deployment
| Task | Tools |
|---|---|
| Model Serving | TensorFlow Serving, TorchServe |
| Containerization | Docker, Kubernetes |
| API Deployment | FastAPI, Flask, AWS Lambda |
🚀 Example:
A finance company deploys a credit risk prediction model using AWS Lambda for real-time scoring.
7. Phase 6: Model Monitoring
After deployment, models must be continuously monitored to detect drift, bias, and performance degradation.
Key Aspects of Model Monitoring
✅ Detect Data Drift – Identify changes in input data distribution.
✅ Monitor Model Performance – Compare real-world predictions to expected values.
✅ Automate Model Retraining – Schedule periodic updates.
Common Tools for Model Monitoring
| Task | Tools |
|---|---|
| Drift Detection | EvidentlyAI, WhyLabs |
| Performance Monitoring | Prometheus, Grafana |
| Model Retraining | Kubeflow, SageMaker Pipelines |
🚀 Example:
A voice assistant company monitors speech recognition accuracy and retrains models when new slang words emerge.
8. Challenges in the ML Lifecycle & Solutions

| Challenge | Solution |
|---|---|
| Poor Data Quality | Use automated data validation tools |
| Model Drift | Set up real-time performance monitoring |
| High Latency in Predictions | Deploy models with optimized inference pipelines |
| Scalability Issues | Use containerized deployment with Kubernetes |
🚀 Trend:
Organizations are adopting MLOps to automate model training, monitoring, and retraining.
9. Future Trends in the ML Lifecycle

🔹 Federated Learning: Train models across multiple devices without sharing raw data.
🔹 Automated ML Pipelines: AI-powered tools to streamline model development.
🔹 Explainable AI (XAI): Enhancing model transparency and fairness.
🔹 Edge AI: Deploying ML models on IoT devices and mobile applications.
🚀 Prediction:
- AutoML will dominate ML development, reducing manual intervention.
- Real-time ML pipelines will power applications like fraud detection and personalized marketing.
10. Final Thoughts
The ML lifecycle is an iterative, structured process that ensures high-quality model development, deployment, and monitoring.
✅ Key Takeaways:
- Business Goal & Problem Framing lay the foundation for ML success.
- Data Processing & Feature Engineering improve model performance.
- Model Training & Tuning ensure accuracy and efficiency.
- Deployment & Monitoring prevent model degradation over time.
💡 How does your company manage ML models in production? Let’s discuss in the comments! 🚀