A Comprehensive Guide to Data Engineering Pipelines in Machine Learning 2024
Introduction
Data Engineering Pipelines are the backbone of every Machine Learning (ML) workflow, ensuring that data is clean, structured, and ready for model training. Without a well-designed data pipeline, even the most advanced ML algorithms will fail to deliver accurate results due to poor data quality.
This guide covers: ✅ The importance of Data Engineering in ML
✅ Key stages of a Data Engineering Pipeline
✅ Best practices for data ingestion, cleaning, and validation
✅ Tools and techniques to automate data workflows
1. Why Data Engineering is Critical in Machine Learning

The phrase “Garbage In, Garbage Out” applies perfectly to machine learning. If the input data is flawed, the model’s predictions will be unreliable.
✅ Impact of Data on ML Models:
- Quality data improves model accuracy and generalization.
- Bad data introduces bias and leads to overfitting or underfitting.
- Scalable data pipelines allow continuous learning and model retraining.
🚀 Example:
A fraud detection model trained on incomplete or biased financial transaction data may incorrectly flag legitimate transactions, leading to poor user experience.
Challenges in Data Engineering for ML
| Challenge | Solution |
|---|---|
| Data Silos | Use centralized data lakes or warehouses. |
| Large-Scale Data Processing | Use distributed frameworks (Apache Spark, Snowflake). |
| Data Quality Issues | Implement validation and cleaning processes. |
| Regulatory Compliance | Ensure GDPR, HIPAA compliance with anonymization. |
2. Stages of a Data Engineering Pipeline

A well-structured data pipeline consists of multiple stages, each focusing on different aspects of data processing.
| Stage | Purpose |
|---|---|
| Data Ingestion | Collect raw data from multiple sources. |
| Exploration & Validation | Analyze data quality and detect errors. |
| Data Wrangling (Cleaning) | Standardize, normalize, and remove inconsistencies. |
| Data Splitting | Prepare training, validation, and test datasets. |
🚀 Example:
An e-commerce platform might build an ML-driven recommendation engine by:
- Ingesting user interactions (clicks, views, purchases).
- Validating data for missing values or anomalies.
- Cleaning and structuring features.
- Splitting data for model training.
3. Data Ingestion: Collecting and Storing Data
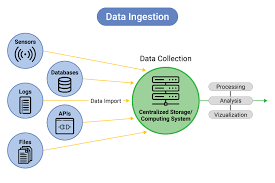
✅ Data Ingestion is the process of collecting data from various systems, databases, and applications to create a centralized dataset.
Key Steps in Data Ingestion
✔ Identify Data Sources – APIs, relational databases, cloud storage, event logs, IoT devices.
✔ Estimate Storage Needs – Plan infrastructure (HDFS, AWS S3, Google BigQuery).
✔ Data Formats – Convert data into structured formats (CSV, JSON, Parquet, Avro).
✔ Backup & Compliance – Anonymize sensitive data to meet privacy laws.
Common Data Ingestion Tools
| Tool | Best For |
|---|---|
| Apache Kafka | Streaming data ingestion |
| AWS Glue | Serverless ETL pipelines |
| Google Cloud Dataflow | Real-time data transformation |
| Airbyte, Fivetran | No-code ETL solutions |
🚀 Example:
A social media analytics platform might use Kafka Streams to collect real-time user engagement data for sentiment analysis.
4. Data Exploration and Validation
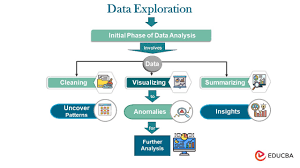
Before using data for ML, it must be explored and validated to identify anomalies and ensure consistency.
Key Actions in Data Exploration
✔ Data Profiling – Calculate min, max, mean, median, standard deviation.
✔ Detect Missing Values – Check for NULLs and decide on imputation strategies.
✔ Attribute Correlation – Identify relationships between variables.
✔ Data Distribution Analysis – Gaussian, uniform, skewed distributions.
✔ Data Visualization – Use histograms, box plots, scatter plots for insights.
Common Tools for Data Validation
| Tool | Best For |
|---|---|
| Great Expectations | Automated data validation |
| Pandas Profiling | Quick data exploration |
| EvidentlyAI | ML-specific drift detection |
🚀 Example:
A healthcare AI company checks patient medical records for outliers and missing values before training a disease prediction model.
5. Data Wrangling (Cleaning & Transformation)
Once data is validated, it undergoes cleaning and transformation to make it suitable for ML models.
Key Data Cleaning Steps
✔ Handle Missing Values – Drop or fill missing data using mean/median/mode.
✔ Fix Outliers – Remove or cap extreme values.
✔ Normalize and Standardize – Scale numerical values for ML models.
✔ Restructure Data – Pivot tables, reshape features, create aggregates.
🚀 Example:
A retail business removes incorrect pricing values and converts categorical data (e.g., product categories) into numerical encodings for model training.
Common Tools for Data Wrangling
| Tool | Best For |
|---|---|
| Pandas, NumPy | Data manipulation in Python |
| Apache Spark | Large-scale data processing |
| dbt (Data Build Tool) | SQL-based transformations |
6. Data Splitting: Preparing Training and Test Sets
Before training ML models, data is split into training, validation, and test sets.
Data Splitting Best Practices
✔ 80-10-10 Rule:
- 80% for training
- 10% for validation
- 10% for testing
✔ Stratified Sampling: Ensure class balance in classification tasks.
✔ Time-Based Splitting: Use past data for training and future data for testing in time-series models.
🚀 Example:
A stock price prediction model ensures that older data is used for training, while recent data is used for validation and testing.
Common Tools for Data Splitting
| Tool | Best For |
|---|---|
| Scikit-learn (train_test_split) | Simple train-test split |
| K-fold Cross Validation | Reduces model variance |
| Time Series Split | Time-dependent models |
7. Best Practices for Building Data Engineering Pipelines
| Best Practice | Why It Matters? |
|---|---|
| Automate ETL Workflows | Reduces manual errors and speeds up data processing |
| Ensure Data Quality with Validation | Prevents biased or incorrect model predictions |
| Use Scalable Cloud Storage | Handles large datasets efficiently |
| Monitor Data Pipelines | Detects failures early and triggers alerts |
| Implement Data Versioning | Enables reproducibility and debugging |
🚀 Trend:
- Serverless data pipelines are reducing maintenance costs.
- Automated ETL workflows using AI are improving data quality.
8. Final Thoughts
Data Engineering Pipelines form the foundation of any Machine Learning system, ensuring clean, high-quality, and structured data for accurate predictions.
✅ Key Takeaways:
- Data Ingestion brings raw data into the system.
- Exploration & Validation ensures data integrity.
- Data Cleaning removes inconsistencies.
- Data Splitting prepares datasets for model training.
- Automation and monitoring improve pipeline efficiency.
💡 What data challenges have you faced in ML projects? Let’s discuss in the comments! 🚀