comprehensive guide to Sequence Models in Deep Learning: RNN, LSTM, and GRU Explained 20
Introduction
In many real-world applications, data comes in the form of sequences. Unlike traditional deep learning models, which assume independent and fixed-size inputs, Sequence Models such as Recurrent Neural Networks (RNNs), Long Short-Term Memory Networks (LSTMs), and Gated Recurrent Units (GRUs) are designed to handle variable-length, time-dependent data.
🚀 Why Are Sequence Models Important?
✔ Captures dependencies between sequential inputs (e.g., text, speech, stock prices).
✔ Maintains memory of past information while making predictions.
✔ Powers applications like sentiment analysis, machine translation, and speech recognition.
Topics Covered
✅ What are Sequence Models?
✅ Recurrent Neural Networks (RNNs) and their limitations
✅ Long Short-Term Memory (LSTM) Networks
✅ Gated Recurrent Units (GRUs) and their advantages
✅ Bidirectional RNNs for improved learning
1. What Are Sequence Models?

Sequence models process sequential data, meaning the order of inputs matters.
🔹 Examples of Sequence Data: ✔ Text: Words in a sentence for machine translation.
✔ Speech: Sound waves for speech recognition.
✔ Time-Series: Stock market predictions based on past data.
🚀 Example: Sentiment Analysis
A model trained on movie reviews predicts positive or negative sentiment.
✔ Input: "The movie was fantastic!"
✔ Output: Positive (+1)
✅ Traditional neural networks fail at such tasks because they do not account for sequential dependencies.
2. Recurrent Neural Networks (RNNs)
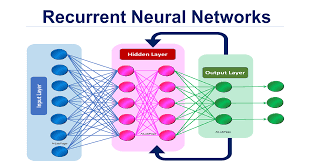
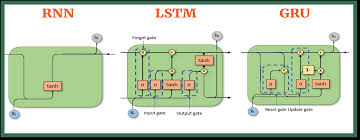
RNNs are the first neural networks designed for sequential data. Unlike feedforward networks, RNNs use hidden states to maintain memory across time steps.
🔹 How RNNs Work: ✔ Takes an input sequence (x1, x2, x3, …, xt).
✔ Passes each input through a hidden state (st) that maintains memory.
✔ The output at each time step (yt) depends on both the current input and past hidden states.
🚀 Mathematical Representation:st=f(Wxt+Ust−1+b)yt=g(Vst+c)s_t = f(Wx_t + Us_{t-1} + b) y_t = g(Vs_t + c) st=f(Wxt+Ust−1+b)yt=g(Vst+c)
where:
- s_t = hidden state at time step t
- x_t = input at time t
- W, U, V = weight matrices
- y_t = output at time t
✅ RNNs help in modeling sequential dependencies, but they suffer from major limitations.
3. Limitations of Standard RNNs

Despite their ability to model sequences, RNNs have key weaknesses:
| Issue | Impact | Solution |
|---|---|---|
| Vanishing Gradient | Past information is forgotten | Use LSTM or GRU |
| Exploding Gradient | Weights grow too large, making training unstable | Apply gradient clipping |
| Short-Term Memory | Cannot retain long-term dependencies | Use attention mechanisms |
| Computational Inefficiency | Cannot be parallelized effectively | Use Transformer models |
🚀 Example: Machine Translation ✔ If an RNN translates "The cat sat on the mat." word-by-word, it struggles to retain the subject (cat) while translating later words.
✅ Solution: Use LSTM or GRU to maintain long-term dependencies.
4. Long Short-Term Memory (LSTM) Networks
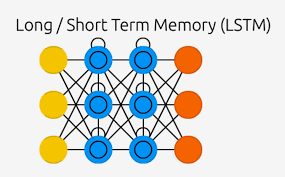
LSTMs solve the vanishing gradient problem by introducing memory cells that explicitly store information.
🔹 Key Components of LSTM: ✔ Forget Gate (f_t): Decides what information to discard.
✔ Input Gate (i_t): Decides what new information to store.
✔ Cell State (C_t): Stores long-term memory.
✔ Output Gate (o_t): Produces output based on memory.
🚀 Mathematical Representation:ft=σ(Wf[ht−1,xt]+bf)it=σ(Wi[ht−1,xt]+bi)C~t=tanh(WC[ht−1,xt]+bC)Ct=ft∗Ct−1+it∗C~tot=σ(Wo[ht−1,xt]+bo)ht=ot∗tanh(Ct)f_t = σ(W_f [h_{t-1}, x_t] + b_f) i_t = σ(W_i [h_{t-1}, x_t] + b_i) C̃_t = tanh(W_C [h_{t-1}, x_t] + b_C) C_t = f_t * C_{t-1} + i_t * C̃_t o_t = σ(W_o [h_{t-1}, x_t] + b_o) h_t = o_t * tanh(C_t) ft=σ(Wf[ht−1,xt]+bf)it=σ(Wi[ht−1,xt]+bi)C~t=tanh(WC[ht−1,xt]+bC)Ct=ft∗Ct−1+it∗C~tot=σ(Wo[ht−1,xt]+bo)ht=ot∗tanh(Ct)
where:
- f_t, i_t, o_t = forget, input, and output gates
- C_t = memory cell
- h_t = hidden state
🚀 Example: Speech Recognition ✔ LSTMs can remember longer phonetic dependencies for better speech translation.
✅ LSTMs significantly improve sequence learning compared to standard RNNs.
5. Gated Recurrent Units (GRUs)
GRUs are a simplified version of LSTMs, maintaining similar performance with fewer parameters.
🔹 Key Differences Between GRUs and LSTMs: ✔ GRUs do not have a separate cell state (C_t).
✔ Uses an Update Gate (z_t) instead of input + forget gates.
✔ Uses a Reset Gate (r_t) for updating hidden state selectively.
🚀 Mathematical Representation:zt=σ(Wz[ht−1,xt]+bz)rt=σ(Wr[ht−1,xt]+br)h~t=tanh(Wh[rt∗ht−1,xt]+bh)ht=(1−zt)∗ht−1+zt∗h~tz_t = σ(W_z [h_{t-1}, x_t] + b_z) r_t = σ(W_r [h_{t-1}, x_t] + b_r) h̃_t = tanh(W_h [r_t * h_{t-1}, x_t] + b_h) h_t = (1 – z_t) * h_{t-1} + z_t * h̃_t zt=σ(Wz[ht−1,xt]+bz)rt=σ(Wr[ht−1,xt]+br)h~t=tanh(Wh[rt∗ht−1,xt]+bh)ht=(1−zt)∗ht−1+zt∗h~t
where:
- z_t = update gate
- r_t = reset gate
- h_t = new hidden state
🚀 Example: Weather Prediction ✔ GRUs are used to predict temperature trends over long periods.
✅ GRUs perform similarly to LSTMs but are computationally faster.
6. Bidirectional RNNs (BRNNs)
Standard RNNs process input left to right. Bidirectional RNNs (BRNNs) process input in both directions, improving context understanding.
🔹 Why Use BRNNs? ✔ Improves performance in NLP tasks (e.g., Named Entity Recognition).
✔ Accounts for future context in addition to past information.
🚀 Example: Part-of-Speech Tagging ✔ "The dog runs" – If "dog" is recognized as a noun, it helps classify "runs" as a verb.
✅ BRNNs are ideal for tasks where future context helps current predictions.
7. Comparing RNN, LSTM, and GRU
| Feature | RNN | LSTM | GRU |
|---|---|---|---|
| Memory Retention | Short-term | Long-term | Long-term |
| Vanishing Gradient Issue | Yes | No | No |
| Computational Cost | Low | High | Medium |
| Best Used For | Simple sequences | Long dependencies | Faster training |
🚀 Choosing the Right Model: ✔ Use RNNs for simple, short sequences.
✔ Use LSTMs when long-term dependencies are crucial.
✔ Use GRUs for efficient training with similar performance to LSTMs.
✅ Each architecture balances complexity, training time, and memory requirements.
8. Conclusion
Sequence models like RNNs, LSTMs, and GRUs are essential for learning from time-dependent data.
✅ Key Takeaways
✔ RNNs process sequential data but struggle with long-term dependencies.
✔ LSTMs introduce memory cells to solve the vanishing gradient problem.
✔ GRUs simplify LSTMs while maintaining strong performance.
✔ Bidirectional RNNs improve context understanding.
💡 Which sequence model do you use in your projects? Let’s discuss in the comments! 🚀
Would you like a hands-on tutorial on implementing LSTMs and GRUs using TensorFlow? 😊
4o