comprehensive guide to Imitation Learning: Teaching AI by Demonstration 2024
Introduction

Imitation Learning (IL) is a machine learning approach where an AI agent learns by observing expert demonstrations rather than through trial-and-error reinforcement learning. This method is widely used in robotics, self-driving cars, gaming AI, and healthcare, where training an agent from scratch is inefficient or impractical.
This blog explores how imitation learning works, its key algorithms, and real-world applications.
1. What is Imitation Learning?
Imitation Learning enables an AI system to learn decision-making strategies from expert demonstrations instead of interacting with an environment through reinforcement learning.
🔹 Key Elements of Imitation Learning: ✔ Expert Demonstrations – The AI system watches an expert perform a task.
✔ State-Action Pairs – The AI maps each state to an action.
✔ Policy Learning – The AI generalizes from expert behavior to new situations.
🚀 Example: AI for Self-Driving Cars
✔ AI observes human drivers and learns how to steer, accelerate, and brake in different environments.
✔ Over time, AI models mimic human driving behavior with high accuracy.
✅ Imitation Learning accelerates AI training by leveraging human expertise.
2. Behavioral Cloning: The Simplest Form of Imitation Learning
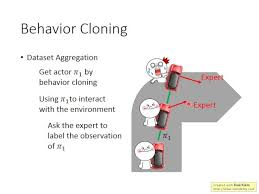
Behavioral Cloning (BC) is a supervised learning approach where an AI learns to directly imitate an expert’s actions.
🔹 How Behavioral Cloning Works: 1️⃣ Collect demonstrations from human experts.
2️⃣ Train a neural network to predict actions given a state.
3️⃣ Deploy the AI agent to perform tasks based on learned behavior.
📌 Formula for Policy Learning in Behavioral Cloning:π(a∣s)=P(a∣s,θ)π(a|s) = P(a | s, θ) π(a∣s)=P(a∣s,θ)
where π is the policy and θ are learned model parameters.
🚀 Example: AI in Video Games
✔ AI learns turning angles and acceleration patterns from human players.
✔ Used in autonomous racing simulators and robotics competitions.
✅ Behavioral Cloning is effective but suffers from compounding errors when encountering new situations.
3. Challenges in Behavioral Cloning
While BC is simple and effective, it has three major limitations:
🚧 1. Compounding Errors
- If the AI makes a slight mistake, it can deviate from expert demonstrations, leading to irrecoverable errors.
🚧 2. Poor Generalization
- AI struggles with unseen scenarios (e.g., a self-driving car trained in sunny weather fails in the rain).
🚧 3. No Exploration
- The AI never learns beyond the expert’s actions, limiting its ability to adapt to new challenges.
📌 Key Challenge: How do we teach AI to correct its mistakes and generalize better?
✅ Solution: Use advanced imitation learning methods like DAGGER and Inverse Reinforcement Learning (IRL).
4. DAGGER: A More Robust Imitation Learning Approach
DAGGER (Dataset Aggregation) improves on behavioral cloning by allowing the AI to request expert corrections when it makes mistakes.
✅ How DAGGER Works:
✔ Train the AI using behavioral cloning.
✔ Let the AI perform tasks autonomously.
✔ If the AI makes mistakes, the expert provides corrections.
✔ The AI updates its policy using both its own actions and expert feedback.
🚀 Example: AI-Powered Drone Flying
✔ A drone learns to fly autonomously but makes mistakes.
✔ A human pilot provides corrections, improving the AI’s robustness.
✅ DAGGER allows interactive learning, making AI more adaptable.
5. Inverse Reinforcement Learning (IRL): Learning the Reward Function

Inverse Reinforcement Learning (IRL) is a powerful approach where an AI infers the expert’s reward function from observed demonstrations.
✅ Why Use IRL?
- In standard RL, we define a reward function manually.
- In IRL, the AI learns what the expert values and optimizes accordingly.
🛠️ How IRL Works
✔ The AI observes expert demonstrations.
✔ It infers a hidden reward function that explains the observed behavior.
✔ It optimizes its policy using reinforcement learning (RL).
🚀 Example: AI for Traffic Optimization
✔ AI watches human traffic controllers manage traffic lights.
✔ It learns hidden patterns and optimizes traffic flow autonomously.
✅ IRL enables AI to generalize expert behaviors to new situations.
6. Generative Adversarial Imitation Learning (GAIL): Combining GANs and IRL

Recent research has combined IRL with Generative Adversarial Networks (GANs) to improve learning efficiency.
✅ How GAIL Works
1️⃣ Generator (AI policy) tries to imitate expert behavior.
2️⃣ Discriminator (Evaluator) tries to distinguish between expert actions and AI actions.
3️⃣ Feedback Loop: The AI improves until it is indistinguishable from expert behavior.
🚀 Example: AI for Motion Capture Animation
✔ AI learns realistic human movement by imitating dancers and athletes.
✔ Used in film animation and virtual reality.
✅ GAIL helps AI achieve expert-level performance in highly dynamic tasks.
7. Applications of Imitation Learning
Imitation learning is transforming AI-driven automation in various industries.
| Industry | Use Case |
|---|---|
| Autonomous Vehicles | AI mimics human driving for safer self-driving cars |
| Healthcare AI | AI-assisted robotic surgery |
| Robotics | AI-powered robotic arms learn manual tasks |
| Gaming AI | AI NPCs learn player behavior for realistic interactions |
| Finance | AI learns stock trading strategies from expert investors |
🚀 Example: AI in Healthcare
✔ AI-assisted surgery robots learn from human surgeons.
✔ Used in AI-powered robotic surgical assistants.
✅ Imitation Learning makes AI more intuitive and human-like.
8. When to Use Imitation Learning?
| Scenario | Best Approach |
|---|---|
| AI needs to mimic human expertise | Behavioral Cloning |
| AI must recover from mistakes | DAGGER (Dataset Aggregation) |
| AI must generalize expert behavior | Inverse Reinforcement Learning (IRL) |
| AI needs to generate human-like actions | GAIL (Generative Adversarial Imitation Learning) |
📌 Key Takeaway:
Use Imitation Learning when mistakes are costly or exploration is dangerous.
9. Final Thoughts: The Future of Imitation Learning
Imitation Learning is revolutionizing AI, allowing systems to learn efficiently from human expertise rather than relying on random exploration.
🚀 Key Takeaways
✔ Behavioral Cloning is effective but suffers from compounding errors.
✔ DAGGER improves AI learning by actively incorporating expert corrections.
✔ Inverse Reinforcement Learning (IRL) lets AI infer expert intentions.
✔ GAIL refines AI’s ability to mimic human behavior using adversarial training.
✔ Imitation Learning is widely used in robotics, self-driving cars, and gaming AI.
💡 What’s Next?
Future research in imitation learning + reinforcement learning will create AI systems capable of autonomous decision-making in dynamic environments.
👉 Do you think imitation learning will lead to fully autonomous AI? Let’s discuss in the comments! 🚀