A comprehensive Guide to Federated Learning with TensorFlow: Building Models on Decentralized Data 2024

Machine learning (ML) has proven transformative across industries, but as we scale the use of AI, privacy concerns and data centralization become pressing issues. Federated Learning (FL) is an innovative approach that addresses these concerns by training machine learning models decentrally, without requiring raw data to be shared between devices or stored on central servers. This approach ensures data privacy while still enabling the collaborative development of powerful models.
In this blog, we’ll explore the core concepts of Federated Learning, provide a step-by-step guide to implementing FL with TensorFlow, and walk you through a practical example using the MNIST dataset.
What is Federated Learning?

Federated Learning (FL) is a distributed machine learning method that allows multiple edge devices (such as mobile phones, laptops, or IoT devices) to collaboratively train a machine learning model. The key benefit of FL is that data never leaves its original device. Instead, each device trains the model locally and shares the model updates (weights) with a central server. The server aggregates these updates and applies them to the global model, which is then redistributed to the clients.
This decentralized approach solves major problems in AI development:
- Privacy: Sensitive data remains on the device.
- Efficiency: Only model updates (which are much smaller than raw data) are communicated, reducing bandwidth consumption.
- Scalability: FL allows model training across millions of devices without centralizing data.
Basic Architecture of Federated Learning
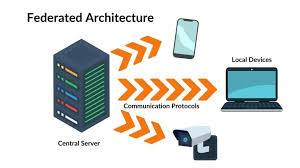
Federated Learning operates with the following architecture:
- Central Server: The server coordinates the training process and manages the global model.
- Clients (Edge Devices): These are devices (mobile phones, PCs, etc.) that have local data. Each client trains the model on its local dataset and sends the updates to the central server.
- Model Training Cycle:
- The server distributes the initial model to the clients.
- Each client trains the model on its local data for a set number of epochs.
- Clients send their updated model weights to the server.
- The server aggregates the model weights (usually by averaging) and updates the global model.
- The updated model is then sent back to the clients for further training.
This cycle repeats until the model converges, or a predefined number of communication rounds is reached.
Implementing Federated Learning with TensorFlow

In this section, we’ll develop a simple Federated Learning example using TensorFlow and the MNIST dataset.
Step 1: Data Preprocessing
First, we load the MNIST dataset, a classic dataset of handwritten digits, and preprocess the images to make them suitable for training.
pythonCopyimport cv2
import numpy as np
from imutils import paths
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
from sklearn.utils import shuffle
def load(paths):
data = []
labels = []
for imgpath in paths:
im_gray = cv2.imread(imgpath, cv2.IMREAD_GRAYSCALE)
image = np.array(im_gray).flatten()
label = imgpath.split(os.path.sep)[-2]
data.append(image / 255)
labels.append(label)
return data, labels
- Loading Images: The images are loaded as grayscale and flattened into vectors to feed them into a multi-layer perceptron (MLP).
- Label Binarization: Labels are one-hot encoded to prepare them for training.
Step 2: Split Data into Training and Testing Sets
pythonCopyimage_paths = list(paths.list_images(img_path))
image_list, label_list = load(image_paths)
lb = LabelBinarizer()
label_list = lb.fit_transform(label_list)
X_train, X_test, y_train, y_test = train_test_split(image_list, label_list, test_size=0.1, random_state=42)
- Train-Test Split: We split the dataset into training (90%) and testing (10%) sets.
Step 3: Creating Federated Clients
In Federated Learning, clients represent isolated datasets that train the model on their data. For simplicity, we simulate this process by creating 10 data shards, each representing data for one client.
pythonCopydef create_clients(image_list, label_list, num_clients=10, initial='clients'):
client_names = ['{}_{}'.format(initial, i+1) for i in range(num_clients)]
data = list(zip(image_list, label_list))
random.shuffle(data)
size = len(data)//num_clients
shards = [data[i:i + size] for i in range(0, size*num_clients, size)]
return {client_names[i]: shards[i] for i in range(len(client_names))}
clients = create_clients(X_train, y_train, num_clients=10, initial='client')
- Client Data Sharding: We split the training data into 10 shards, each assigned to a client. Each shard will be used for local training.
Step 4: Federated Averaging
Federated Averaging is the algorithm used in FL to combine model updates from all clients. After each client trains the model on its local data, the model weights are sent to the server, where they are averaged.
pythonCopydef federated_averaging(client_weights):
avg_weights = []
for weights_list in zip(*client_weights):
avg_weights.append(np.mean(weights_list, axis=0))
return avg_weights
- Model Aggregation: After collecting the local model weights from all clients, the server averages them to update the global model.
Step 5: Model Training
Each client trains its local model using the data shard assigned to it. The local models are then aggregated into a global model.
pythonCopy# Model setup
class SimpleMLP:
@staticmethod
def build(shape, classes):
model = tf.keras.Sequential([
tf.keras.layers.Dense(200, input_shape=(shape,), activation="relu"),
tf.keras.layers.Dense(200, activation="relu"),
tf.keras.layers.Dense(classes, activation="softmax")
])
return model
global_model = SimpleMLP.build(784, 10)
# Federated Training Loop
for comm_round in range(100):
client_weights = []
for client_data in clients.values():
local_model = SimpleMLP.build(784, 10)
local_model.compile(optimizer='SGD', loss='categorical_crossentropy', metrics=['accuracy'])
local_model.set_weights(global_model.get_weights())
local_model.fit(client_data, epochs=1, verbose=0)
client_weights.append(local_model.get_weights())
global_weights = federated_averaging(client_weights)
global_model.set_weights(global_weights)
- Local Training and Federated Averaging: Each client trains a local model for one epoch. After that, the model weights are aggregated, and the global model is updated.
Step 6: Testing the Global Model
Finally, we evaluate the global model on the test set after each communication round.
pythonCopydef test_model(X_test, Y_test, model):
logits = model.predict(X_test)
loss = tf.keras.losses.CategoricalCrossentropy(from_logits=True)(Y_test, logits)
acc = accuracy_score(tf.argmax(logits, axis=1), tf.argmax(Y_test, axis=1))
print(f'Accuracy: {acc:.3%} | Loss: {loss}')
- Model Evaluation: After each communication round, the global model’s performance is evaluated on the test set.
Conclusion: Federated Learning for Privacy-Preserving AI
Federated Learning is a powerful approach for training machine learning models on decentralized data while ensuring privacy. By bringing the model to the data instead of the other way around, Federated Learning enables organizations to collaborate without sharing sensitive data, making it ideal for industries like healthcare, finance, and mobile applications.
This tutorial demonstrates how TensorFlow can be used to implement a basic Federated Learning setup, simulating the communication between clients and a central server to collaboratively train a model. With continued improvements in secure aggregation and privacy-preserving techniques, Federated Learning will become an even more crucial part of the AI landscape, ensuring that machine learning remains both powerful and privacy-conscious.