comprehensive guide to Accelerating Decision Trees: Optimizing Training with Parallelism and Distribution 2024
Decision trees are one of the most popular algorithms in machine learning due to their simplicity and effectiveness in both classification and regression tasks. However, as the size of datasets continues to grow, training decision trees can become computationally expensive. To tackle this, parallelism and distribution techniques are increasingly used to speed up the training process. In this blog, we’ll explore how parallelized and distributed decision trees improve performance and reduce training times, making them more feasible for large-scale machine learning applications.
What Are Decision Trees?
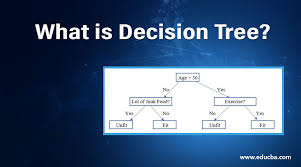
Decision trees are a supervised learning method used for both classification and regression tasks. A decision tree works by splitting the data into subsets based on the most significant feature at each node, creating a structure that can be used to make predictions about new, unseen data.
The tree consists of:
- Root Node: Contains all of the data.
- Internal Nodes: Represent questions about features (e.g., “Is
xi > v?”). - Leaf Nodes: Represent the final output (classification or regression value).
The goal of decision tree algorithms is to build the tree by choosing the best splits at each node to minimize classification error or maximize information gain.
Challenges in Decision Tree Training

The training of decision trees can be slow due to the large amount of computation required to evaluate potential split points for each feature. The feature selection process involves calculating various criteria (e.g., entropy, Gini impurity) for each possible split, which can be computationally expensive, especially with large datasets.
Moreover, traditional decision tree algorithms often rely on repeated sorting of data for evaluating splits, which becomes a bottleneck when dealing with large datasets. Optimizing this process using parallelism and distribution techniques can significantly speed up training.
Optimizing Decision Trees with Parallelism
Multi-Core Parallelism
One of the simplest ways to speed up decision tree training is by using multi-core CPUs. This allows the algorithm to perform multiple tasks simultaneously. For instance, training multiple tree nodes can be parallelized, where different cores handle different portions of the tree or different features for splitting.
GPU Parallelism
For more intensive tasks, Graphics Processing Units (GPUs) can be used to accelerate decision tree training. GPUs are designed for parallel computations and can handle thousands of operations simultaneously, making them particularly well-suited for ML algorithms like decision trees.
- Histogram Binning: A key optimization technique for decision trees is histogram binning. This method avoids the need to sort data multiple times by precomputing histograms for each feature. Using GPUs to update these histograms can significantly speed up the process.
Hybrid Parallelism
A hybrid approach combines both CPU and GPU power to handle different parts of the decision tree construction process. While GPUs can handle histogram updates efficiently, CPUs can be used for tasks like splitting the tree and managing other algorithmic details.
Distributed Decision Trees
When data exceeds the capacity of a single machine, distributed decision tree training comes into play. The idea is to distribute the training workload across multiple machines, each of which handles a portion of the dataset.
Distributed Algorithm Overview
In a distributed setup, each machine is assigned a partition of the dataset. These machines then:
- Construct local histograms of their data partition.
- Send local histograms to a central master node.
- The master node aggregates these histograms to evaluate potential split points.
- The master node then sends the best split point to the workers, which split the data and send the results back to the master.
This approach allows decision tree training to scale effectively across large datasets, reducing the time it takes to build the tree.
Challenges in Distributed Training

While distributed decision tree training can significantly speed up the process, it also comes with challenges:
- Communication Overhead: Transferring large amounts of data between nodes can become a bottleneck, especially as the number of machines increases.
- Global View of Data: Each machine only has access to a portion of the data, making it difficult to evaluate global features across the entire dataset.
- Load Balancing: Ensuring that each machine has an equal workload is critical for efficient parallelism. If one machine is overburdened while others are idle, performance can degrade.
Improving Distributed Training with Voting Schemes
To reduce communication overhead, some distributed algorithms use a voting scheme. In this approach:
- Each machine first evaluates possible split points locally.
- Machines vote for the best features to split on, and the master node aggregates these votes.
- The master then selects the top features for splitting and distributes this information back to the workers.
This method reduces the need for constant communication and helps achieve better scalability as the number of nodes increases.
Performance and Speedup
The performance improvements from parallelizing and distributing decision tree training can be substantial:
- Histogram construction and split evaluation can be parallelized, significantly reducing the time taken to evaluate all potential split points.
- In a distributed setting, training time can be drastically reduced by dividing the dataset across multiple nodes. For example, using a 2-node system can lead to significant speedup, and using more nodes can result in even faster training times.
- Hybrid systems that use both CPU and GPU power for histogram updates and tree splitting offer optimal performance.
GPU and Hybrid Implementation for Improved Performance
A key observation is that decision tree algorithms are often bandwidth-bound, meaning that memory bandwidth can limit performance. By combining CPU and GPU resources, it is possible to maximize memory bandwidth and reduce the data transfer bottleneck.
- GPU-only implementations are faster than CPU-only methods for large datasets, but the initial memory setup and data transfer overhead can reduce the speedup.
- Hybrid approaches that allocate specific tasks to CPUs and GPUs can achieve better performance, especially for large datasets, by balancing the workload and minimizing data transfer times.
Conclusion: Parallelism and Distribution for Faster Decision Trees
The performance of decision tree algorithms can be significantly improved by leveraging parallelism and distributed training. Whether using multi-core CPUs, GPUs, or a hybrid of both, the key to optimizing decision trees lies in handling the computationally intensive tasks, like histogram construction and split evaluation, in parallel.
Distributed decision trees, using multiple machines or nodes, allow for the scaling of tree construction to massive datasets, such as those in big data applications. With further advancements in GPU parallelism, hybrid systems, and communication-efficient distributed algorithms, decision trees can continue to be a powerful and efficient tool for machine learning on large-scale datasets.
By adopting parallelized and distributed strategies, machine learning practitioners can build faster, more efficient decision trees, unlocking new possibilities in fields ranging from finance to healthcare, where large datasets are common and performance is critical.