comprehensive guide to the Basics of ML System Optimization and Distributed Computing 2024
As machine learning continues to grow in complexity, the need for system optimization has become more pronounced. From model training to inference, machine learning algorithms can be computationally expensive, especially when dealing with large datasets and complex models. Optimizing the performance of these algorithms ensures that they can scale and work efficiently on modern hardware platforms. This blog will explore the key principles of machine learning (ML) system optimization and distributed computing, highlighting how parallelization and distributed systems can dramatically improve the performance of machine learning models.
What is ML System Optimization?

Machine learning system optimization focuses on improving the computational performance of machine learning algorithms across various hardware platforms. This involves optimizing the way algorithms run on multi-core CPUs, GPUs, clusters, and even constrained devices such as mobile phones. The goal is to achieve better scalability, faster training times, and reduced resource consumption, allowing ML models to be deployed more effectively on a wide range of devices.
Key topics in ML system optimization include:
- Parallel computing to speed up training and inference.
- Distributed computing to handle large-scale datasets and models.
- Optimization techniques to improve algorithm efficiency and scalability.
Why Distributed Computing Matters in ML

Machine learning models are growing in size and complexity, making it increasingly difficult to train them on a single machine. Distributed computing has emerged as a critical technique to address these challenges. By leveraging multiple machines or computing nodes, we can split the computational workload, reduce training times, and scale up models for large datasets.
In the context of machine learning, distributed computing involves splitting data, computations, and tasks across multiple machines to perform parallel processing and distributed storage. This not only speeds up the training process but also enables the handling of massive datasets that cannot fit into the memory of a single machine.
Key Benefits of Distributed Computing in ML
- Faster Processing: Distributed systems can handle multiple computations simultaneously, significantly reducing the time required to train ML models.
- Scalability: By adding more nodes to the system, distributed computing can handle larger datasets and more complex models.
- Fault Tolerance: Distributed systems can recover from failures, ensuring that the training process continues even if a node crashes.
Distributed System Architecture for ML
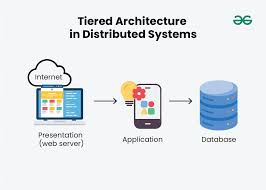
In distributed ML systems, nodes (individual computing resources) are connected through a network, and each node can perform computations and store data. The architecture can be set up in various ways, including centralized, peer-to-peer, and client-server models. In many cases, a master-worker architecture is used, where the master node coordinates the training process, and the worker nodes perform the computations.
Types of Parallelism in ML
There are several types of parallelism that can be applied to ML algorithms, each suited to different aspects of the model training process:
- Data Parallelism: This approach involves splitting the dataset across multiple nodes, with each node training a portion of the model independently. After each step, the gradients are shared across all nodes to update the global model.
- Model Parallelism: In this approach, the model is divided across multiple nodes, with each node training a specific portion of the model. This is particularly useful for large models that cannot fit into the memory of a single machine.
- Task Parallelism: This involves dividing ML tasks into smaller subtasks, which can be executed in parallel across multiple nodes. Each node performs a distinct task, such as data preprocessing, feature extraction, or model evaluation.
Each type of parallelism has its advantages and trade-offs, depending on the size and structure of the model and data.
Popular Frameworks for Distributed ML

There are several powerful frameworks that support distributed machine learning, providing tools and abstractions to make parallel and distributed computing easier for developers:
- Apache Spark: A distributed computing framework that offers high-level APIs for data processing and ML. It supports distributed machine learning through its MLlib library and is ideal for large-scale data processing tasks.
- TensorFlow: A widely-used deep learning framework that supports distributed computing through Distributed TensorFlow. This allows for training deep learning models across multiple GPUs or machines.
- Horovod: A distributed training framework designed for deep learning. It integrates with TensorFlow, PyTorch, and other frameworks to provide efficient scaling across multiple GPUs and nodes.
Fault Tolerance in Distributed ML Systems
Distributed systems need to ensure fault tolerance so that the training process can continue in the event of a failure. Techniques like replication, checkpointing, and distributed consensus algorithms are used to ensure that the system can recover from node failures and resume computations without losing progress.
Scalability Considerations in Distributed ML
Scalability is crucial when dealing with distributed systems in machine learning. A scalable system can handle increasing workloads by adding more resources, such as additional machines or GPUs. The scalability of a distributed system depends on:
- Efficient data partitioning: Properly distributing the data across multiple nodes to reduce communication overhead.
- Optimized communication patterns: Minimizing data transfer between nodes to avoid bottlenecks and improve system performance.
- Resource management: Ensuring that resources are allocated efficiently to prevent overloading of any single node.
Real-World Applications of Distributed ML
Distributed machine learning is used in a wide variety of applications that involve large-scale data and complex models. Some key use cases include:
- Large-Scale Deep Learning: Training models on massive datasets, such as images, videos, or text, which require distributed processing to achieve reasonable training times.
- Distributed Feature Engineering: Accelerating feature extraction and preprocessing steps in ML pipelines by distributing the workload across multiple nodes.
- Real-time Inference: Handling streaming data and making real-time predictions across distributed systems, such as in autonomous vehicles, financial markets, or recommendation systems.
Best Practices and Considerations
When working with distributed machine learning, several best practices should be kept in mind:
- Efficient data partitioning: Split data in a way that minimizes communication overhead and ensures balanced workloads across nodes.
- Optimizing communication: Use efficient communication protocols and minimize unnecessary data transfers to reduce latency.
- Monitoring and debugging: Distributed systems can be complex, so it is important to implement monitoring and debugging tools to track the progress of training and diagnose any issues.
Conclusion: The Power of Distributed Computing in ML
Distributed computing plays a critical role in enabling large-scale machine learning. By leveraging multiple machines and nodes, we can train complex models on massive datasets more efficiently and at a much faster pace. With the right frameworks, parallelism techniques, and best practices, distributed systems provide the scalability, fault tolerance, and speed required for modern machine learning tasks.
As machine learning continues to evolve, distributed systems will remain at the heart of improving the performance and scalability of ML algorithms, opening up new opportunities for research and application in diverse industries.