An comprehensive guide In-Depth Review of Parallel and Distributed Deep Learning 2024
Machine learning, particularly deep learning, has become the cornerstone of many modern applications such as image recognition, natural language processing, and autonomous vehicles. However, the increasing complexity of deep learning models comes with a significant challenge: the computational power required to train and deploy these models. As models become larger, traditional training techniques that rely on a single machine or GPU are no longer sufficient.
This is where parallel and distributed deep learning come into play. These techniques enable the training of large-scale deep learning models across multiple devices, reducing training times and enabling more complex architectures. In this blog, we will explore the concepts of parallelism and distributed deep learning, their benefits, and how they are implemented in modern machine learning workflows.
Why Parallel and Distributed Deep Learning?
Deep learning models often require massive computational power due to the high number of parameters involved. For example, models like ImageNet (which can have up to 100 million parameters) need significant computational resources and memory. Training these models on a single machine can be impractical and time-consuming. Hence, parallel and distributed deep learning techniques are essential for training such large models within a reasonable timeframe.
Here’s why parallel and distributed deep learning is critical:
- Scalability: Deep learning models, especially convolutional neural networks (CNNs) and transformer models, require processing vast amounts of data. These models scale better with parallel processing across multiple machines or GPUs.
- Reduced Training Time: By splitting the task of training across multiple processors, the time taken to train a model can be significantly reduced. Training that might take weeks on a single machine can be done in days or hours using parallelism.
- Handling Large Datasets: Large datasets, like ImageNet, require vast amounts of memory and storage. Distributed deep learning makes it possible to distribute the dataset across multiple machines, enabling the system to process and train the model in parallel.
Types of Parallelism in Deep Learning
Parallelism in deep learning can be categorized into different types, each optimizing a different part of the training process.
1. Data Parallelism

Data parallelism is the most commonly used approach in deep learning. In this method, the model is replicated across multiple devices (GPUs or machines), and each replica processes a subset of the training data. After each forward and backward pass, the updates are aggregated (usually through AllReduce) and synchronized across the devices.
- Advantages:
- Easy to implement with frameworks like TensorFlow and PyTorch.
- Efficient in scenarios where the model fits in memory, but the dataset is large.
- Challenges:
- Communication overhead can slow down training as the number of GPUs increases.
- For very large models, even the model might not fit into a single GPU’s memory, requiring hybrid approaches like model parallelism.
2. Model Parallelism
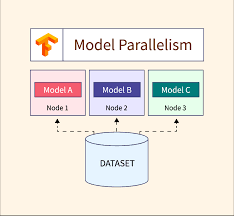
Model parallelism splits the model into different sections, with each section assigned to a separate device. This approach is useful for models that are too large to fit into the memory of a single device. Model parallelism is commonly used for training deep neural networks and transformers, where different layers or components of the model are distributed across devices.
- Advantages:
- Suitable for large models that don’t fit into a single device.
- Reduces memory constraints on individual GPUs.
- Challenges:
- Can lead to communication overhead between different devices, especially when layers need to exchange information during forward and backward passes.
3. Pipeline Parallelism
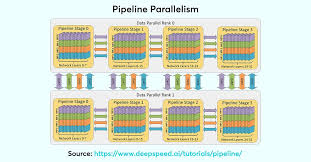
In pipeline parallelism, the model is divided into stages, and each stage is assigned to a separate processor. The data flows through these stages in a pipelined manner, allowing for continuous processing. The key advantage is that while one stage is processing data, the next stage can process a different batch of data, improving throughput.
- Advantages:
- Efficient for sequential models, such as transformers and recurrent neural networks (RNNs).
- Allows for better resource utilization as different stages are handled simultaneously.
- Challenges:
- Complex to implement and tune effectively.
- Idle time in some stages can lead to inefficiencies.
4. Hybrid Parallelism
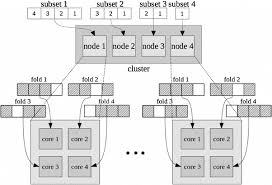
Hybrid parallelism combines both data parallelism and model parallelism to maximize the benefits of both approaches. This method is especially useful when dealing with very large datasets and models that cannot fit entirely in one device’s memory.
- Advantages:
- Scalable for extremely large models and datasets.
- Combines the strengths of data and model parallelism, enabling efficient training.
- Challenges:
- More complex to implement.
- Increased communication overhead and synchronization issues between devices.
Distributed Deep Learning Frameworks
Several frameworks support parallel and distributed deep learning:
- TensorFlow: With TensorFlow Distributed, you can implement data parallelism using MirroredStrategy or TPU pods for large-scale training. TensorFlow also supports model parallelism with tf.distribute and distributed training capabilities.
- PyTorch: PyTorch offers a number of distributed training methods, including DistributedDataParallel and torch.nn.parallel for data and model parallelism. Horovod is also a popular library that can be used with PyTorch to scale across multiple GPUs and machines.
- MXNet: Apache MXNet supports both data parallelism and model parallelism with its Gluon API. MXNet allows easy distribution of models across multiple devices, ensuring effective parallel training.
- Horovod: Originally developed by Uber, Horovod is a distributed deep learning framework designed to make it easy to train models across multiple GPUs and nodes. Horovod leverages Ring-AllReduce to minimize communication overhead and improve training speed.
Challenges in Parallel and Distributed Deep Learning
While parallel and distributed deep learning techniques offer tremendous benefits, they also come with their own set of challenges:
- Synchronization: Keeping the parameters synchronized across devices is a significant challenge, especially in asynchronous methods. Techniques like synchronous SGD (Stochastic Gradient Descent) or Hogwild! try to minimize this issue but require careful tuning.
- Communication Overhead: As the number of devices increases, so does the communication overhead. Efficient methods of communication, like Ring-AllReduce and Hierarchical AllReduce, help mitigate this problem.
- Scalability: While parallelism can reduce training time, scaling to a large number of GPUs or machines can introduce new bottlenecks. Properly managing the distributed memory and ensuring optimal load balancing across devices is critical.
Conclusion
The future of deep learning relies heavily on the ability to scale models across multiple devices efficiently. As the size of models continues to grow, leveraging parallel and distributed deep learning techniques will be crucial for reducing training times and handling large-scale datasets. By employing methods like data parallelism, model parallelism, and hybrid parallelism, and using frameworks like TensorFlow, PyTorch, and Horovod, machine learning engineers can optimize the performance of their deep learning models.
While challenges such as synchronization and communication overhead persist, the continued evolution of parallel computing technologies and optimization techniques will ensure that deep learning models can be trained more efficiently, enabling even more complex and powerful models to emerge.