A Comprehensive Guide to Data Models in Databases 2024
Data models play a critical role in software and machine learning (ML) systems, determining how data is represented, stored, and accessed. Choosing the right data model can impact performance, flexibility, and scalability.
In this blog, we’ll explore different types of data models, their strengths and weaknesses, and how they fit into modern applications.
1. What Are Data Models?
A data model defines how data is structured, stored, and related in a system. It helps in understanding and organizing data attributes.
🔹 Example: A Car can be represented as:
- Structured attributes:
Make, Model, Year, Color - Relational attributes:
Owner, License Plate
Most applications layer multiple data models to optimize performance.
✅ Why Data Models Matter:
- Determine how software is built.
- Affect query performance and storage efficiency.
- Impact scalability and flexibility.
2. Relational Data Model (SQL)
The relational model, introduced by Edgar Codd (1970), is one of the most widely used database models.
A. How It Works
- Data is organized into tables (relations).
- Each row represents a record (tuple).
- Uses Structured Query Language (SQL) for queries.
🔹 Example: A Books Table in a relational database:
| Book_ID | Title | Author | Publisher | Country |
|---|---|---|---|---|
| 1 | Book1 | Pravin | Press1 | USA |
| 2 | Book2 | Alice | Press2 | UK |
B. Normalization in Relational Databases
- Reduces redundancy and improves data integrity.
- Follows 1NF, 2NF, 3NF to optimize storage.
🔹 Challenge: Joins can be expensive for large datasets.
✅ Best Use Case: Structured data where relationships between records matter (e.g., Banking Systems, E-commerce Databases).
3. NoSQL Data Model (Non-Relational)
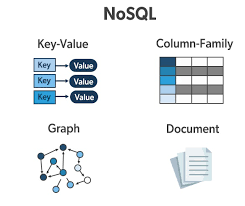
As applications grew in complexity, relational models became restrictive. NoSQL databases offer flexibility.
Types of NoSQL Databases:
- Document Model
- Graph Model
4. Document Model (NoSQL)
- Stores data as self-contained documents (JSON, XML, BSON).
- Each document has a unique key.
- Schema-less – different documents in the same collection can have different fields.
🔹 Example: A Book Document in JSON format:
jsonCopyEdit{
"Title": "Book1",
"Author": "Pravin",
"Publisher": "Press1",
"Country": "USA",
"Sold_as": [
{ "Format": "Paperback", "Price": "20" },
{ "Format": "E-book", "Price": "10" }
]
}
✅ Advantages:
- Faster reads (data is in a single document).
- No strict schema, making it ideal for dynamic applications.
🚨 Challenges:
- Harder to query relationships between documents.
- Joins across documents are inefficient.
🔹 Best Use Case: E-commerce, Blogging Platforms, Content Management Systems.
5. Graph Model (NoSQL)
- Built around relationships rather than tables or documents.
- Uses nodes (entities) and edges (relationships).
🔹 Example: A social network database:
cssCopyEditAlice → [FRIENDS_WITH] → Bob
Alice → [WORKS_AT] → Google
Bob → [LIVES_IN] → New York
✅ Advantages:
- Faster queries on relationships.
- Efficient for recommendation engines, fraud detection, and network analysis.
🚨 Challenges:
- Complex to design and maintain.
🔹 Best Use Case: Social Media Networks, Fraud Detection, Knowledge Graphs.
6. Structured vs. Unstructured Data
| Category | Definition | Example | Best Storage |
|---|---|---|---|
| Structured Data | Follows a predefined schema (table-based). | SQL Databases (MySQL, PostgreSQL) | Data Warehouse |
| Unstructured Data | No fixed schema; can be text, images, videos. | Social Media Posts, Emails, Videos | Data Lake |
✅ Structured Data: Best for transactional applications (Banking, ERP, CRM).
✅ Unstructured Data: Best for big data storage and analytics (Hadoop, AWS S3).
7. Choosing the Right Data Model
| Factor | Relational Model (SQL) | NoSQL (Document/Graph) |
|---|---|---|
| Flexibility | Schema-defined | Schema-less |
| Scalability | Vertical Scaling | Horizontal Scaling |
| Joins & Relationships | Strong | Weak (except Graph) |
| Performance for Reads | Slower | Faster |
🔹 When to Choose SQL:
- Data has well-defined relationships (Banking, ERP, CRM).
- You need ACID compliance (Atomicity, Consistency, Isolation, Durability).
🔹 When to Choose NoSQL:
- Data is semi-structured or unstructured.
- The system needs to scale horizontally (Social Media, Big Data, IoT).
8. Hybrid Approach: Best of Both Worlds
- Many modern databases support both relational and NoSQL models.
- PostgreSQL and MySQL allow JSON document storage alongside SQL tables.
🔹 Example: A Retail System:
- Orders & Transactions (SQL)
- User Preferences & Browsing History (NoSQL)
9. Data Warehouses vs. Data Lakes
- Data Warehouse: Stores structured data for business intelligence.
- Data Lake: Stores raw, unstructured data for AI/ML.
🔹 Example: Netflix uses a Data Lake to store all raw user interactions and a Data Warehouse to generate reports.
10. Best Practices for Data Modeling

✅ Choose SQL for structured, transactional data.
✅ Use NoSQL (Document/Graph) for flexible, scalable applications.
✅ Optimize queries for fast retrieval and storage efficiency.
✅ Store raw data in Data Lakes before processing.
✅ Normalize relational databases for consistency, but avoid over-normalization.
Final Thoughts
The right data model depends on business needs, scalability, and query complexity. While SQL remains dominant for transactional systems, NoSQL is gaining popularity for scalable and flexible applications.
💡 Which data model do you prefer for your projects? Let us know in the comments! 🚀