Advanced Data Pipelines: Development, Execution, and Best Practices 2024
As organizations become more data-driven, the complexity of data analytics pipelines continues to grow. Data pipelines automate the movement, transformation, and analysis of data, ensuring high-quality insights for decision-making, machine learning (ML), and business intelligence (BI).
This guide explores: ✅ The need for advanced data analytics pipelines
✅ Use cases and types of data pipelines
✅ Stages in a modern data pipeline
✅ People, tools, and best practices
1. Why Are Data Pipelines Critical for Analytics?
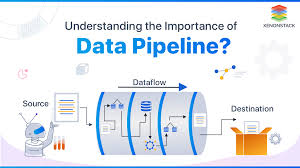
Despite being a valuable business asset, most organizations struggle with immature data analytics processes. The lack of structured, automated, and repeatable workflows results in:
- Slow data processing that doesn’t meet business demands.
- High error rates due to manual intervention.
- Inefficiencies in collaboration between IT and business teams.
🚀 Example:
A financial institution that relies on manual data reporting may face delayed fraud detection, leading to financial losses.
✅ Solution: Automated, scalable, and robust data pipelines.
2. Origin of Data Pipelines
Data pipelines emerged from the big data revolution, particularly with the rise of data lakes. These platforms gave analysts, data scientists, and engineers unrestricted access to raw data from various sources.
🔹 How They Evolved:
- Traditional ETL (Extract, Transform, Load) pipelines were batch-oriented and rigid.
- The shift to real-time analytics and machine learning required event-driven, streaming pipelines.
- Modern data pipelines handle both batch and real-time processing, supporting multi-cloud and hybrid architectures.
💡 Example:
A retail company uses real-time data pipelines to track inventory, pricing changes, and customer preferences across multiple locations.
🚀 Trend: Event-driven pipelines (Kafka, Flink) are replacing traditional ETL.
3. Simple vs. Complex Data Pipelines
Data pipelines range from simple to highly complex, depending on business needs.
🔹 Simple Pipeline Example:
➡ Extracts data from an SQL database → Saves it to a CSV file → Places it in a folder.
🔹 Complex Pipeline Example:
➡ Merges data from 10+ sources → Processes missing values → Aggregates sales data by region → Converts formats → Serves insights to BI dashboards.
🚀 Key Takeaway:
The more complex a pipeline, the more orchestration and automation it requires.
4. Two Types of Data Pipelines
| Pipeline Type | Purpose | Challenges |
|---|---|---|
| Development Pipelines | Create code to process data | Code changes impact downstream workflows |
| Execution Pipelines | Run the pipeline in production | Requires high reliability & monitoring |
✅ Best Practice:
- Development pipelines focus on building transformations.
- Execution pipelines focus on operational stability.
💡 Example:
A data engineering team builds a development pipeline for testing, while the BI team relies on an execution pipeline for dashboards.
5. Key Stages in a Data Pipeline
Most modern data analytics pipelines follow these stages:
A. Data Ingestion
✅ Extracts raw data from multiple sources:
- Databases (PostgreSQL, MySQL, Oracle)
- APIs and Web Scrapers
- Streaming platforms (Kafka, AWS Kinesis)
- Cloud Storage (Google Cloud Storage, AWS S3)
🚀 Challenge: Handling high-volume, unstructured data.
B. Data Transformation
✅ Cleans, enriches, integrates, and models data for downstream systems.
🔹 Common Data Transformations:
| Type | Purpose |
|---|---|
| Data Cleansing | Removes missing or incorrect data |
| Aggregation | Summarizes data (e.g., total sales per region) |
| Feature Engineering | Prepares data for machine learning models |
💡 Example:
A healthcare company standardizes patient data across hospitals before analysis.
🚀 Challenge: Maintaining data consistency across multiple transformations.
C. Data Analysis & Machine Learning
✅ Data is refined, analyzed, and modeled to generate insights.
🔹 Example Use Cases:
- Fraud detection models analyze financial transactions.
- Predictive analytics optimize customer segmentation.
- Operational analytics track real-time inventory changes.
🚀 Challenge: Keeping data synchronized between analysis & ML models.
D. Data Visualization & Reporting
✅ Data is served to BI tools, ML models, and applications.
🔹 Popular BI & Data Serving Platforms:
| Platform | Best For |
|---|---|
| Tableau, Power BI | Business Intelligence & Reports |
| Google Looker | Data visualization & exploration |
| Feature Stores | Serving ML-ready datasets |
🚀 Challenge: Ensuring low-latency queries for high-concurrency workloads.
6. Key Players in Data Pipeline Management
Modern data pipelines span multiple functions, requiring different specialists.
| Role | Responsibility |
|---|---|
| Data Engineer | Builds ETL pipelines & transforms raw data |
| BI Developer | Creates reports & dashboards |
| ML Engineer | Trains & deploys ML models |
| Software Developer | Embeds data into applications |
🚀 Best Practice:
Use orchestration tools (Airflow, Dagster) to coordinate work across teams.
7. Micro-Pipelines: Breaking Down Complexity
🔹 Why Use Micro-Pipelines?
- Modularizes pipeline stages to reduce errors.
- Enables independent testing & development.
- Accelerates deployment & debugging.
🔹 Example Micro-Pipeline Stages: 1️⃣ Requirement Gathering – Agile teams define data needs.
2️⃣ Development – Engineers build and test transformations.
3️⃣ Testing & Validation – Data quality checks ensure accuracy.
4️⃣ Deployment & Monitoring – Live pipelines track errors.
🚀 Trend: DataOps methodologies improve pipeline efficiency.
8. Orchestration, Automation, & Testing
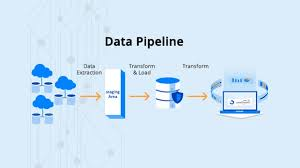
🔹 Why Automate Data Pipelines?
- Reduces manual intervention & deployment errors.
- Improves pipeline monitoring & failure detection.
- Speeds up data integration & analytics workflows.
✅ Popular Pipeline Orchestration Tools:
| Tool | Purpose |
|---|---|
| Apache Airflow | Workflow scheduling & automation |
| AWS Glue | Serverless ETL |
| Dagster | ML pipeline orchestration |
🚀 Best Practice:
Set up automated testing & alerts to detect failures early.
9. Final Thoughts
As data analytics pipelines evolve, businesses must focus on scalability, automation, and monitoring.
✅ Key Takeaways:
- Data pipelines enable automated analytics & ML workflows.
- Complex pipelines require orchestration & monitoring.
- Micro-pipelines improve modularity & error handling.
- Testing is critical to maintaining data integrity.
💡 How does your company manage its data pipelines? Let’s discuss in the comments! 🚀