Breaking the Memory Wall in Deep Learning with ZeRO: A Game-Changer for Large-Scale Model Training 2024
Training large-scale deep learning models comes with its own set of challenges, particularly when it comes to memory consumption. As models grow, so does their memory footprint, leading to the notorious “memory wall” where GPUs are unable to handle the data. ZeRO (Zero Redundancy Optimizer) is a revolutionary optimizer designed to address this issue by breaking down the memory wall and enabling the training of massive models without the need for additional hardware.
In this blog, we’ll dive deep into ZeRO and how it optimizes memory usage, allowing us to train models with billions of parameters efficiently across multiple GPUs. We’ll explore ZeRO’s stages, its ability to scale out large models, and the techniques that make it possible to train models previously thought untrainable.
The Memory Wall Problem in Deep Learning
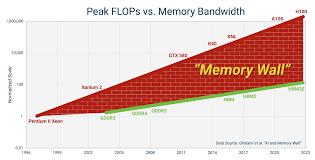
As deep learning models grow in size, their memory requirements grow exponentially. Consider the example of large language models like GPT-3, which contains 175 billion parameters. These models not only require significant computation but also a vast amount of memory to store optimizer states, gradients, and parameters during training. This leads to an overwhelming demand for GPU memory, and in many cases, GPUs run out of memory before the model can be trained effectively.
This challenge becomes more pronounced as the number of parameters increases, causing standard optimization techniques to fail when applied to large models.
Introducing ZeRO: Zero Redundancy Optimizer

ZeRO (Zero Redundancy Optimizer) is a memory-efficient optimizer designed to eliminate memory redundancy in distributed training, allowing large models to be trained without exceeding GPU memory limits. ZeRO works by partitioning the memory used by the model across multiple GPUs, ensuring that each GPU only stores a portion of the data, significantly reducing memory usage.
ZeRO’s key contributions are:
- Memory Efficiency: ZeRO partitions the optimizer states, gradients, and parameters, eliminating redundancies across GPUs and reducing the overall memory footprint.
- Scalability: ZeRO scales with the number of GPUs, enabling the training of models with up to trillions of parameters on a single node or across multiple nodes.
- Increased Throughput: ZeRO improves training throughput by reducing memory bottlenecks and enabling faster computations.
ZeRO’s Three Stages of Memory Optimization
ZeRO operates in three stages, each progressively improving memory efficiency:
ZeRO Stage 1: Partitioning Optimizer States
- In the first stage, ZeRO partitions the optimizer states (such as momentum and variance in optimizers like Adam) across GPUs, eliminating redundancy.
- This reduces the memory footprint of each GPU without losing the effectiveness of the optimizer.
ZeRO Stage 2: Partitioning Gradients
- The second stage extends the memory partitioning to gradients, ensuring that each GPU only holds a portion of the gradient information.
- By distributing the gradients, ZeRO reduces the communication overhead between GPUs and improves training speed.
ZeRO Stage 3: Partitioning Parameters
- In the third stage, ZeRO partitions the model parameters themselves across GPUs.
- This allows training large models that exceed the memory limits of a single GPU by splitting the model weights across multiple devices.
ZeRO-Offload: Extending Memory Beyond GPUs
In addition to partitioning memory across GPUs, ZeRO introduces ZeRO-Offload, a technique that leverages CPU and NVMe storage to further reduce the memory burden on GPUs. ZeRO-Offload stores optimizer states and parameters in CPU memory instead of GPU memory, only transferring them to GPUs as needed.
This allows for:
- Training larger models with fewer GPUs.
- Efficient memory management by offloading less critical data to CPU or NVMe storage.
- Increased model scalability, enabling the training of models with over 1 trillion parameters.
ZeRO-Offload significantly boosts the memory capacity of systems and allows for training models like GPT-3 on a single node with multiple GPUs.
Benefits of ZeRO in Large-Scale Model Training
ZeRO addresses several critical issues in large-scale model training:
- Memory Efficiency: By partitioning optimizer states, gradients, and parameters, ZeRO ensures that each GPU holds only a fraction of the total memory, making it possible to train models that were previously too large to fit in memory.
- Scalability: ZeRO scales with the number of GPUs, allowing for parallelization across devices and enabling the training of billion-parameter models.
- Training Throughput: By optimizing memory usage and parallelizing computation, ZeRO increases training throughput, making it possible to achieve high performance while using fewer GPUs.
- Cost-Effectiveness: ZeRO enables efficient use of resources, reducing the need for expensive hardware upgrades and enabling the training of large models on more affordable systems.
ZeRO in Practice: Training Large Models
ZeRO has already been used to train several large models, including:
- GPT-3: ZeRO made it possible to train GPT-3, a 175 billion parameter model, using a combination of model parallelism and ZeRO-powered data parallelism.
- Turing-NLG: A large language model by Microsoft, which used ZeRO to optimize memory usage and training throughput.
Performance Comparison: ZeRO vs. Other Techniques
ZeRO provides a clear advantage in training large models compared to traditional optimization techniques like Data Parallelism (DP) and Model Parallelism (MP). While DP replicates model parameters across GPUs, leading to redundancy and high memory consumption, ZeRO reduces this redundancy, allowing for more efficient use of memory and faster training.
- ZeRO vs. Data Parallelism (DP): ZeRO outperforms DP by partitioning memory and reducing redundancy, enabling the training of much larger models with fewer GPUs.
- ZeRO vs. Model Parallelism (MP): ZeRO does not require a complete rewrite of the model and can be integrated with existing model parallelism strategies, making it a more flexible and efficient solution.
Scaling ZeRO: Beyond the GPU Memory Wall
ZeRO not only works within GPU memory limits but also extends the memory capacity of the training system by utilizing CPU and NVMe storage. This is particularly useful in environments where GPU memory is limited, as it offloads portions of the model to CPU memory, reducing the reliance on GPU memory and allowing for even larger models.
Conclusion: Breaking the Memory Wall with ZeRO
ZeRO is a groundbreaking optimization technique that has successfully broken the memory wall in deep learning, enabling the training of massive models with trillions of parameters. By partitioning optimizer states, gradients, and parameters across multiple GPUs, and by using ZeRO-Offload to offload data to CPU and NVMe storage, ZeRO makes it possible to train large models more efficiently and cost-effectively.
With ZeRO, the dream of training large-scale AI models that were once thought untrainable is now a reality. This technology not only pushes the boundaries of what’s possible in AI research but also democratizes access to powerful models, making them more accessible to developers and researchers working with limited resources.
ZeRO is transforming how we think about deep learning at scale and is paving the way for even more advanced models in the future.