Building a Custom Data Pipeline: A Step-by-Step comprehensive Guide 2024
Data pipelines are essential for automating data movement, transformation, and analysis across various sources. A custom data pipeline allows businesses to process structured and unstructured data, ensuring efficiency, reliability, and scalability.
This guide explores: ✅ What is a data pipeline?
✅ Key components of a custom data pipeline
✅ Step-by-step implementation
✅ Best practices for scalable pipelines
1. What is a Data Pipeline?
A data pipeline is a series of processes that ingest, process, transform, store, and serve data for analytics and decision-making.
🔹 Why Do We Need a Data Pipeline?
- Eliminates manual data handling
- Ensures data consistency across applications
- Enables real-time & batch data processing
- Supports analytics & machine learning models
🚀 Example:
An e-commerce company ingests customer purchase data from multiple sources (web, mobile, POS systems) and sends it to a cloud warehouse for sales analytics.
2. Key Components of a Custom Data Pipeline
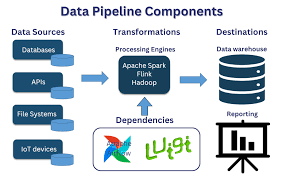
| Component | Purpose | Example Tools |
|---|---|---|
| Data Ingestion | Collects raw data | Kafka, Flink, Fivetran |
| Data Transformation | Cleans & preprocesses | dbt, Pandas, Spark |
| Data Storage | Stores processed data | Snowflake, BigQuery, S3 |
| Orchestration | Automates workflows | Apache Airflow, Dagster |
| Data Serving | BI & ML model integration | Looker, Tableau, MLflow |
🚀 Trend: Organizations are adopting serverless & real-time data pipelines to improve efficiency.
3. Step-by-Step Implementation of a Custom Data Pipeline

Let’s break down the key steps to build a custom data pipeline.
Step 1: Define Your Data Sources
✅ Identify where the data is coming from:
- APIs (Twitter API, Weather API)
- Databases (PostgreSQL, MySQL)
- Streaming Events (Kafka, IoT sensors)
🚀 Example:
A retail business ingests real-time sales transactions from multiple locations into a central data system.
Step 2: Extract Data (Ingestion)
✅ Implement an ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) process.
🔹 Batch Ingestion:
- Uses scheduled jobs to fetch data periodically.
- Tools: Apache Sqoop, AWS Glue, Fivetran.
🔹 Real-Time Streaming:
- Captures live data for immediate analysis.
- Tools: Kafka, Kinesis, Pub/Sub.
🚀 Best Practice: Use streaming pipelines for time-sensitive applications like fraud detection.
Step 3: Transform Data (Processing & Cleaning)
✅ Apply data cleansing, enrichment, and feature engineering.
🔹 Common Transformations:
| Transformation Type | Example |
|---|---|
| Data Cleansing | Removing NULL values & duplicates |
| Schema Mapping | JSON → Parquet for faster queries |
| Aggregation | Summarizing daily sales data |
🔹 Tools for Data Transformation:
- SQL-Based: dbt (Data Build Tool), Apache Hive
- Python-Based: Pandas, PySpark
🚀 Example:
A fintech company normalizes financial transactions to detect fraudulent activities.
Step 4: Store Data in a Warehouse or Lake
✅ Choose a data storage solution based on your needs.
🔹 Types of Storage:
| Storage Type | Best For |
|---|---|
| Data Warehouse | Structured analytics (Snowflake, BigQuery) |
| Data Lake | Unstructured & semi-structured data (AWS S3, Azure Data Lake) |
| Lakehouse | Combines warehouse & lake (Databricks) |
🚀 Best Practice: Use Parquet or ORC formats for optimized queries.
Step 5: Orchestrate the Pipeline
✅ Automate data workflows with orchestration tools.
🔹 Popular Orchestration Tools:
| Tool | Best For |
|---|---|
| Apache Airflow | DAG-based workflow automation |
| Prefect | Python-native orchestration |
| Dagster | ML & ETL pipeline automation |
🚀 Example:
A healthcare company automates daily ETL workflows with Airflow DAGs.
Step 6: Serve Data for Analytics & ML
✅ Make data available for BI dashboards and machine learning models.
🔹 Common BI & Analytics Tools:
| Tool | Use Case |
|---|---|
| Tableau | Data visualization |
| Looker | Self-service BI |
| MLflow | ML model tracking |
🚀 Example:
A ride-sharing app feeds real-time traffic data into ML models to optimize routes.
4. Challenges & Best Practices

| Challenge | Solution |
|---|---|
| High Latency | Use streaming ingestion (Kafka, Flink) |
| Data Quality Issues | Implement validation checks with Great Expectations |
| Pipeline Failures | Monitor with Airflow, Prometheus |
| High Storage Costs | Use cold storage for infrequently accessed data |
🚀 Future Trend: AI-driven self-healing pipelines that detect & resolve failures automatically.
5. Final Thoughts
A custom data pipeline enables businesses to process, analyze, and visualize data efficiently. By integrating cloud-native tools and automation, companies can unlock real-time insights, improve decision-making, and drive AI adoption.
✅ Key Takeaways:
- Custom pipelines automate ETL, ELT, and streaming workflows.
- Storage solutions (Data Lakes, Warehouses) depend on data needs.
- Orchestration (Airflow, Dagster) ensures smooth pipeline execution.
- BI & ML tools (Tableau, MLflow) enable real-time insights.
💡 What challenges have you faced in building data pipelines? Let’s discuss in the comments! 🚀