comprehensive guide to Advanced Parallelism Techniques for Machine Learning System Optimization 2024
As machine learning (ML) systems grow more complex and data-intensive, the need for efficient parallelism and distributed computing techniques becomes critical to achieve faster training, improved performance, and scalability. In this blog, we dive deeper into the essential concepts of parallelizing ML programs, with a particular focus on the different types of parallelism: data parallelism, model parallelism, and pipeline parallelism.
What is an ML Program?
An ML program is not just a sequence of deterministic steps. Unlike algorithms like sorting, which follow a fixed sequence of steps to achieve the result, ML programs are optimization-centric. They focus on finding approximate solutions, such as minimizing a loss function using local updates, and they typically require iterative convergence to find the optimal model parameters.
The core of an ML program is an iterative convergence process where parameters (e.g., weights in a neural network) are updated across multiple iterations. The update function (Δ) computes the changes in the model’s parameters, and the aggregation function (F) combines the updates from multiple data samples.
Mathematically, an ML program can be defined using the Iterative-Convergence (IC) equation:
At=update(data,At−1)A_t = update(data, A_{t-1})At=update(data,At−1)
Where:
- AtA_tAt represents the model’s parameters at training step ttt,
- update(data, A_{t-1}) is a function that updates these parameters based on the data at step t−1t-1t−1.
Three Dimensions of Parallelism in ML
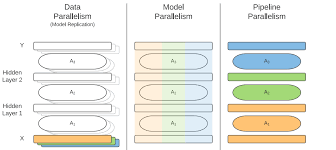
To optimize ML programs, we need to parallelize different parts of the model training. Here, we explore three main types of parallelism that can be applied to ML systems:
1. Data Parallelism

Data parallelism is the simplest and most common approach for speeding up ML model training. It works by splitting the dataset into equal parts and processing these parts in parallel across multiple devices (e.g., GPUs or CPUs). Once the updates are computed, they are aggregated to perform a single optimization step.
In this approach, the model is fully replicated on each worker, and each worker processes a subset of the data. Afterward, the model parameters are aggregated, and an optimization step is performed.
Why it Works:
- Increased Efficiency: Each worker processes a smaller chunk of data, allowing for faster computations.
- Batch Size: Larger batches lead to more accurate gradient estimates and faster convergence. Since data parallelism uses multiple workers, larger batches can be processed with lower computational time per sample.
Advantages:
- Easy to implement with available frameworks (e.g., PyTorch, TensorFlow).
- Model-agnostic—works with any model architecture (CNNs, Transformers, GANs).
- Predictable speed improvements with the increase in worker devices (e.g., using 4 GPUs results in up to 4x speedup).
Disadvantages:
- Requires the entire model to fit into the memory of a single worker device.
- Communication overhead when aggregating updates across devices, which becomes significant with a large model.
2. Model Parallelism
Model parallelism is useful when the model is too large to fit into the memory of a single device. Instead of replicating the model across multiple workers, model parallelism splits the model’s layers across devices. Each device is responsible for computing the forward and backward passes for a specific portion of the model.
Why it Works:
- Memory Efficiency: By splitting the model, each device only needs to store a portion of the model, making it possible to train large models that wouldn’t fit on a single device.
- Parallel Computation: The model’s layers can be processed in parallel across multiple devices, improving computation speed for large, deep models.
Examples of Parallelizable Layers:
- Linear Layer: Split the weight matrix across devices and compute the dot product in parallel.
- Convolutional Layer: Distribute the filters across devices and perform convolutions in parallel.
- Multi-head Attention: Apply parallel processing to matrix multiplications involved in attention mechanisms in transformer models.
Advantages:
- Greatly reduces memory usage, allowing for the training of larger models with more parameters.
- Can speed up the computation of certain layers if parallelized effectively.
Disadvantages:
- Complex to implement, as model splitting depends on the specific architecture.
- High communication costs, as synchronization is required between devices after each layer is processed.
3. Pipeline Parallelism
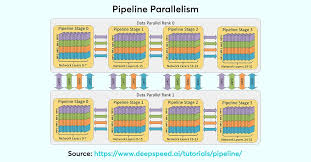
Pipeline parallelism is a powerful alternative to model parallelism, designed to reduce memory requirements and improve throughput. In this approach, the model is split into sequential stages, with each stage processed on a different device. Data flows through these stages in a pipeline, where each worker processes different parts of the data in parallel.
How It Works:
- Sequential Stage Splitting: Divide the model into stages and assign each stage to a different device.
- Data Flow: The model processes batches of data sequentially across stages. For instance, the output of one stage is passed as input to the next.
- All Forward, All Backward (AFAB): After processing the forward pass for a batch, each worker computes the backward pass for its respective stage.
Filling the Pipeline:
The efficiency of pipeline parallelism improves as workers begin processing new data before the previous workers finish their calculations. By filling idle times and optimizing resource utilization, pipeline parallelism maximizes throughput.
Memory Efficiency:
- Memory usage is reduced since each worker only stores a part of the model.
- Workers only store activations for their assigned portion of the model, making it possible to scale models to larger architectures with limited memory.
Advantages:
- Reduces memory usage by splitting the model and allowing for larger models to be processed.
- Increases throughput by minimizing idle times, as workers process different parts of the data concurrently.
Disadvantages:
- May lead to lower utilization if the stages are not balanced efficiently.
- Requires careful tuning to ensure that the pipeline is filled optimally and idle times are minimized.
Hybrid Parallelism: Combining Approaches
In many real-world scenarios, a combination of the above parallelism techniques can be used to optimize ML training further. For example:
- Hybrid Data and Pipeline Parallelism: Data parallelism is applied across machines, while pipeline parallelism is used within each machine to distribute the model layers across GPUs.
- Combining Model and Pipeline Parallelism: Different branches of a model (e.g., in inception networks) can use model parallelism, while the overall pipeline uses pipeline parallelism to split the stages.
When to Use Which Approach?
- Data Parallelism: Best for small models that fit within a single GPU, or when you want fast convergence with a smaller batch size.
- Model Parallelism: Ideal when the model is too large to fit on a single device and has multiple parallel branches or paths.
- Pipeline Parallelism: Suitable for sequential models (e.g., CNNs, Transformers) where a single device cannot handle the entire model, but splitting the model into stages is feasible.
- Hybrid Parallelism: Use when working with extremely large models or datasets that need both data and model parallelism to scale efficiently.
Conclusion: Scaling ML with Parallelism
Machine learning models are growing in size and complexity, and so is the need for efficient parallel and distributed training methods. Pipeline parallelism, model parallelism, and data parallelism are essential techniques that help improve memory usage, increase throughput, and enable the training of large models across multiple devices. By leveraging the right parallelization approach—or combining them effectively—you can unlock the full potential of modern ML systems, enabling faster training and more scalable AI applications.
As machine learning continues to evolve, optimizing parallelism strategies will remain central to ensuring that the growing demands of data, model size, and computational power are met efficiently.