comprehensive guide to Attention and Transformers in Deep Learning 2024
Introduction
Attention mechanisms and Transformers have revolutionized natural language processing (NLP), computer vision, and sequence-based tasks. Unlike traditional Recurrent Neural Networks (RNNs), which process sequences sequentially, Transformers use self-attention to process entire sequences in parallel, improving efficiency and scalability.
🚀 Why Learn About Transformers?
✔ Overcome RNN limitations (e.g., vanishing gradients, long dependencies).
✔ Enable parallel computation for faster training.
✔ Achieve state-of-the-art results in NLP and Vision (GPT, BERT, ViTs).
✔ Used in applications like chatbots, speech translation, and image recognition.
Topics Covered
✅ The evolution of sequence models: RNN → LSTM → Transformers
✅ The Attention Mechanism and how it works
✅ The Transformer architecture
✅ Self-Attention and Multi-Head Attention
✅ Vision Transformers (ViTs)
1. From RNNs to Transformers: Why Did We Need Change?
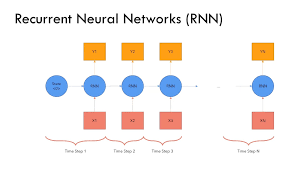
Traditional sequence models like RNNs and LSTMs process input sequentially, making them slow and inefficient for long sequences.
| Model | Advantages | Disadvantages |
|---|---|---|
| RNNs | Captures sequence dependencies | Struggles with long-range dependencies |
| LSTMs/GRUs | Better memory retention | Still suffers from sequential processing bottlenecks |
| Transformers | Uses self-attention, parallel processing | Computationally expensive |
🚀 Example: Machine Translation ✔ RNNs struggle with translating long sentences because they forget earlier words.
✔ LSTMs help but still process words one by one.
✔ Transformers process all words in parallel, making translation much faster!
✅ The need for faster, more scalable models led to the development of Attention and Transformers.
2. The Attention Mechanism: How It Works
Attention allows models to focus on important parts of input sequences, improving their understanding of context.
🔹 How Attention Works in NLP: ✔ Instead of relying on the last hidden state (like RNNs), each word attends to all words in the input sequence.
✔ Assigns different importance (weights) to words based on their relevance.
🚀 Example: Machine Translation ✔ In translating "I love deep learning" to French, attention helps focus on each word independently rather than just the final hidden state.
✅ Attention solves RNN’s problem by letting each word dynamically “look” at all words in the input sequence.
3. The Transformer Architecture
Introduced in 2017 by Vaswani et al. (“Attention Is All You Need”), the Transformer is a fully attention-based model, removing recurrence altogether.
🔹 Key Features of Transformers: ✔ Encoders & Decoders: The Transformer consists of stacked layers of encoders and decoders.
✔ Self-Attention: Each token in the sequence attends to every other token.
✔ Multi-Head Attention: Improves the model’s ability to capture different relationships.
✔ Positional Encoding: Adds order information since there is no recurrence.
🚀 Example: How Transformers Work ✔ Encoder: Takes input words → converts them into numerical embeddings → applies self-attention.
✔ Decoder: Uses attention to generate words in an output sentence one by one.
✅ Transformers outperformed RNNs by handling sequences in parallel and improving long-range dependencies.
4. Self-Attention: The Core of Transformers
Self-attention allows each word to interact with all other words in a sequence, assigning importance to each.
✅ Steps in Self-Attention
1️⃣ Compute similarity scores between words (e.g., “The cat sat” → “cat” is more related to “sat” than “The”).
2️⃣ Apply Softmax to normalize attention weights.
3️⃣ Multiply the attention weights with the input embeddings to get a weighted sum.
🚀 Example: Self-Attention in Sentence Processing ✔ Sentence: "She drove the car because it was raining."
✔ Self-attention ensures “it” is correctly linked to “car”, improving model understanding.
✅ Unlike RNNs, Transformers analyze all words simultaneously, making them significantly faster.
5. Multi-Head Attention: Expanding Self-Attention
Instead of computing one set of attention scores, Multi-Head Attention applies attention multiple times in parallel.
🔹 Why Use Multi-Head Attention? ✔ Different attention heads capture different aspects of meaning.
✔ Improves the model’s ability to understand context more effectively.
✔ Allows multiple perspectives on relationships between words.
🚀 Example: Translating “bank” in Different Contexts ✔ “I deposited money in the bank.” → Focuses on financial institution.
✔ “He sat by the river bank.” → Focuses on geographic location.
✅ Multi-Head Attention enables models to understand words in multiple contexts simultaneously.
6. Vision Transformers (ViTs): Applying Transformers to Images
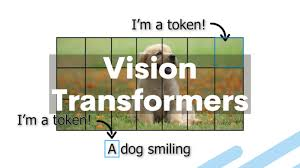
CNNs (Convolutional Neural Networks) dominated image processing, but in 2020, Vision Transformers (ViTs) challenged their dominance.
🔹 How ViTs Work: ✔ Divide an image into patches (16×16 pixels).
✔ Flatten patches and embed them like tokens in NLP.
✔ Apply self-attention instead of convolution.
🚀 Example: Object Detection in Images ✔ A ViT processes an image as a sequence of patches, allowing it to capture global relationships better than CNNs.
✅ ViTs outperform CNNs in large-scale vision tasks when trained on sufficient data.
7. Comparing RNNs, LSTMs, and Transformers

| Feature | RNN | LSTM/GRU | Transformer |
|---|---|---|---|
| Handles long-range dependencies | ❌ No | ✅ Yes | ✅ Yes |
| Processes input in parallel | ❌ No | ❌ No | ✅ Yes |
| Memory Efficiency | ❌ Low | ✅ Medium | ✅ High |
| State-of-the-art in NLP & Vision | ❌ No | ✅ Partially | ✅ Yes |
🚀 Choosing the Right Model: ✔ Use RNNs for simple sequential data.
✔ Use LSTMs when long-term dependencies are crucial.
✔ Use Transformers for state-of-the-art performance in NLP and vision.
✅ Transformers are now the default for all major AI applications.
8. Applications of Transformers

Transformers are used in various domains beyond NLP, including:
🔹 Natural Language Processing ✔ GPT-4 & BERT: Text generation, chatbots (ChatGPT).
✔ T5 & BART: Text summarization, machine translation.
🔹 Computer Vision ✔ Vision Transformers (ViTs): Image classification, object detection.
🔹 Audio & Speech Processing ✔ Whisper AI (OpenAI): Speech-to-text.
🚀 Example: AI-Powered Customer Support ✔ GPT-based chatbots understand customer queries better than rule-based bots.
✅ Transformers dominate AI applications across multiple fields.
9. Conclusion
Attention mechanisms and Transformers have transformed AI, replacing RNNs/LSTMs with faster, more efficient models.
✅ Key Takeaways
✔ Self-attention enables parallel processing and long-range dependencies.
✔ Transformers outperform RNNs/LSTMs in NLP and Vision tasks.
✔ Multi-Head Attention improves context understanding.
✔ Vision Transformers (ViTs) extend Transformers to image processing.
💡 Are you using Transformers in your projects? Let’s discuss in the comments! 🚀
Would you like a hands-on tutorial on building Transformer models using TensorFlow? 😊
4o