comprehensive guide to CNN Architectures: From LeNet to ResNet 2024
Introduction
Convolutional Neural Networks (CNNs) are the backbone of modern computer vision applications. Over the years, CNN architectures have evolved, improving accuracy, efficiency, and scalability. Each architecture introduces innovative techniques that enhance the ability of neural networks to extract features from images.
🚀 Why Learn CNN Architectures?

✔ Better image recognition performance
✔ Faster and more efficient deep learning models
✔ Ability to transfer learned features across tasks
✔ State-of-the-art architectures power applications like self-driving cars, medical diagnostics, and facial recognition
Topics Covered
✅ LeNet-5: The first CNN architecture
✅ AlexNet: Breakthrough in deep learning
✅ VGG-16: Standardized deep networks
✅ GoogLeNet/Inception: Efficient deep models
✅ ResNet: The power of residual learning
✅ Transfer Learning: Using pre-trained models
1. LeNet-5: The Foundation of CNNs

LeNet-5, developed by Yann LeCun in 1998, was the first CNN architecture, designed for handwritten digit recognition (MNIST dataset).
🔹 Key Features of LeNet-5: ✔ Convolutional Layers: Feature extraction using 5×5 filters.
✔ Pooling Layers: Subsampling (average pooling) for dimension reduction.
✔ Tanh Activation: Instead of ReLU, Tanh was used to introduce non-linearity.
✔ Fully Connected (FC) Layers: The final classifier.
🚀 Architecture: [CONV-POOL-CONV-POOL-FC-FC]
✅ LeNet-5 proved CNNs could automatically extract relevant features, reducing the need for manual feature engineering.
2. AlexNet: The Breakthrough in Deep Learning (2012)

In 2012, AlexNet won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) by reducing the top-5 error from 26% to 15.3%, a major leap in deep learning.
🔹 Key Innovations of AlexNet: ✔ First CNN to use ReLU activation, enabling faster convergence.
✔ Local Response Normalization (LRN) (no longer widely used).
✔ Used GPU acceleration (NVIDIA GTX 580), making deep learning feasible.
✔ Dropout Regularization (0.5) to prevent overfitting.
✔ Data Augmentation (image flipping, contrast variations).
🚀 Architecture:
- 11×11 Conv Layer (stride 4) to extract features from large images.
- Max Pooling (3×3) to reduce dimensionality.
- 5 Convolutional Layers followed by Fully Connected Layers.
✅ AlexNet demonstrated the power of deep learning for large-scale image classification.
3. VGG-16: Standardizing Deep Networks (2014)
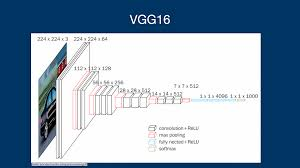
Developed by the Visual Geometry Group (VGG), VGG-16 introduced a standardized deep network architecture.
🔹 Key Features of VGG-16: ✔ All convolutional layers use 3×3 filters (simplifying architecture).
✔ Increased depth (16 layers) improved accuracy.
✔ All max-pooling layers use 2×2 pooling.
✔ Fully connected layers generalize well to other tasks.
✔ VGG-16 and VGG-19 were introduced; VGG-19 had slightly better performance.
🚀 Why VGG-16? ✔ Easy to implement in deep learning frameworks.
✔ Great feature extractor for Transfer Learning.
✔ Trained on ImageNet, useful for many vision applications.
✅ VGG-16 made deep networks more structured, but at the cost of high computational requirements (~138 million parameters).
4. GoogLeNet/Inception: Efficient Deep Networks (2014)
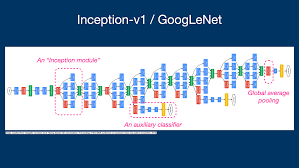
Google introduced GoogLeNet (Inception v1) in 2014, winning ILSVRC with a top-5 error of 6.7%.
🔹 Key Features of GoogLeNet: ✔ Inception Modules – Instead of stacking convolutional layers, parallel convolutions (1×1, 3×3, 5×5) were used to extract multiple feature types.
✔ Global Average Pooling instead of fully connected layers (reducing overfitting).
✔ Deep (22 layers) but computationally efficient (only 5 million parameters).
✔ No Fully Connected Layers – Reducing memory usage significantly.
🚀 Why Inception Networks? ✔ Smaller and more efficient than VGG-16.
✔ Can scale to deep architectures without massive parameter growth.
✔ Variants like Inception v2, v3, and v4 further improved efficiency.
✅ GoogLeNet/Inception Networks paved the way for deeper, more efficient architectures.
5. ResNet: The Power of Residual Learning (2015)
Residual Networks (ResNets), developed by Microsoft Research, solved the vanishing gradient problem in deep networks by introducing skip connections (residual learning).
🔹 Key Innovations of ResNet: ✔ Introduced Residual Connections – Skip connections allow information to pass through deeper layers without loss.
✔ Trained 152-layer deep networks, making them the deepest models at that time.
✔ Used Batch Normalization after every convolutional layer.
✔ Revolutionized deep learning, winning ILSVRC 2015 with a 3.57% error rate.
🚀 Why ResNet? ✔ Overcomes degradation problems in deep networks.
✔ Can train extremely deep models (up to 1000 layers!).
✔ Used in object detection (YOLO, Faster R-CNN) and segmentation (U-Net, Mask R-CNN).
✅ ResNet made deep learning more practical for complex real-world problems.
6. Comparing CNN Architectures
| Architecture | # Layers | Parameters | Strengths |
|---|---|---|---|
| LeNet-5 | 7 | ~60K | Simple, good for small images (MNIST) |
| AlexNet | 8 | ~60M | First deep CNN, fast with GPUs |
| VGG-16 | 16 | ~138M | Standardized deep network |
| GoogLeNet | 22 | ~5M | Efficient, reduced parameters |
| ResNet-152 | 152 | ~60M | Enables very deep networks |
✅ Each CNN architecture builds on previous breakthroughs, making models deeper, faster, and more efficient.
7. Transfer Learning: Using Pre-Trained CNNs
Instead of training a CNN from scratch, transfer learning allows using a pre-trained model and fine-tuning it on a new dataset.
🔹 Popular Pre-Trained CNN Models: ✔ VGG-16/VGG-19 – General-purpose feature extractors.
✔ ResNet-50/101 – Highly accurate for object recognition.
✔ Inception v3 – Great for large-scale image analysis.
🚀 Example: Using ResNet for Medical Diagnosis ✔ Train on ImageNet, then fine-tune on X-ray images for pneumonia detection.
✅ Transfer learning accelerates training and improves accuracy with less data.
8. Conclusion
CNN architectures have evolved dramatically, from LeNet-5 to ResNet, improving performance, efficiency, and scalability.
✅ Key Takeaways
✔ LeNet-5 introduced CNNs for digit recognition.
✔ AlexNet proved deep learning’s superiority in computer vision.
✔ VGG-16 standardized deep networks.
✔ GoogLeNet/Inception made deep networks more efficient.
✔ ResNet introduced skip connections for ultra-deep networks.
✔ Transfer Learning enables faster and more accurate model training.
💡 Which CNN architecture do you use in your projects? Let’s discuss in the comments! 🚀
Would you like a Python tutorial on implementing CNN architectures using TensorFlow? 😊