Comprehensive Guide to Data Science Infrastructure: Components, Challenges, and Best Practices 2024
The data science infrastructure is the backbone of machine learning (ML) and artificial intelligence (AI) applications. It enables the collection, storage, processing, and deployment of data-driven models, ensuring scalability and efficiency.
This guide covers: ✅ The paradigm shift in data science infrastructure
✅ The lifecycle of a data science project
✅ Key components of modern data science infrastructure
✅ Challenges and best practices
1. The Paradigm Shift in Data Science Infrastructure

🔹 Why is data science becoming more accessible?
- Advancements in cloud computing, open-source tools, and automation are making AI/ML easier to implement.
- Faster data processing frameworks (like Apache Spark, TensorFlow, and Kubernetes) allow real-time model training.
- The focus is shifting from making ML possible to making ML easy.
✅ Outcome: More companies can leverage AI for real-world applications like self-driving cars, fraud detection, and personalized marketing.
🚀 Challenge: Ensuring that the infrastructure supports rapid experimentation and deployment.
2. The Lifecycle of a Data Science Project
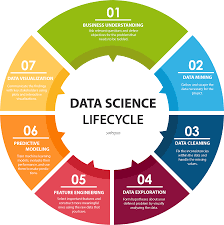
All ML and AI projects follow a structured lifecycle, regardless of industry.
🔹 Stages of a Data Science Project: 1️⃣ Data Collection – Gathering structured & unstructured data.
2️⃣ Data Preprocessing – Cleaning, transforming, and engineering features.
3️⃣ Model Development – Selecting and training ML models.
4️⃣ Evaluation & Experimentation – Comparing different model versions.
5️⃣ Deployment & Monitoring – Integrating models into production systems.
6️⃣ Iteration & Improvement – Continuously refining model performance.
💡 Example:
A bank’s fraud detection system continuously updates its ML model based on new fraudulent patterns detected in real-time transactions.
🚀 Best Practice: Use a scalable infrastructure that supports continuous model iteration.
3. Key Components of Data Science Infrastructure
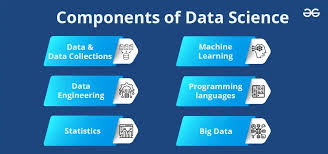
A robust data science infrastructure consists of several layers, each responsible for specific tasks.
A. Data Warehouse
✅ What is it?
A centralized storage system for structured and semi-structured data.
✅ Key Features:
- Ensures data durability and security.
- Optimized for fast retrieval and analytics.
- Supports SQL-based querying.
🔹 Popular Data Warehouses:
| Service | Provider |
|---|---|
| Amazon Redshift | AWS |
| Google BigQuery | Google Cloud |
| Snowflake | Multi-cloud |
💡 Example:
A retail company stores sales transaction data in Google BigQuery to analyze customer purchase patterns.
B. Compute Resources
✅ What is it?
The infrastructure required to process large datasets and train ML models.
✅ Key Features:
- Supports distributed computing (multi-GPU, multi-node clusters).
- Provides on-demand scalability.
- Compatible with deep learning frameworks (TensorFlow, PyTorch).
🔹 Popular Compute Platforms:
| Technology | Use Case |
|---|---|
| Kubernetes | Containerized ML workloads |
| Apache Spark | Distributed data processing |
| AWS SageMaker | Cloud-based ML model training |
🚀 Best Practice: Use auto-scaling compute clusters to handle workload spikes efficiently.
C. Job Scheduler
✅ What is it?
Manages automated data workflows and ML training jobs.
✅ Key Features:
- Ensures timely retraining of ML models.
- Manages large-scale data pipeline executions.
- Reduces manual workload for data engineers.
🔹 Popular Job Scheduling Tools:
| Tool | Purpose |
|---|---|
| Apache Airflow | Workflow orchestration |
| AWS Step Functions | Serverless workflow automation |
| Dagster | ML pipeline scheduling |
💡 Example:
A fintech company uses Airflow to automatically retrain credit risk models every night.
🚀 Best Practice: Implement monitoring tools to prevent pipeline failures.
D. Versioning
✅ What is it?
Tracks different versions of data, models, and experiments.
✅ Key Features:
- Supports model reproducibility.
- Allows side-by-side comparison of different ML versions.
- Prevents model degradation over time.
🔹 Popular Versioning Tools:
| Tool | Use Case |
|---|---|
| DVC (Data Version Control) | Dataset versioning |
| MLflow | Model tracking |
| Git & GitHub | Code version control |
💡 Example:
A data scientist tests multiple versions of a recommendation algorithm and selects the best-performing one for production.
🚀 Best Practice: Store both datasets and ML models with proper version tags.
E. Model Operations (MLOps)
✅ What is it?
Ensures ML models remain accurate and reliable in production.
✅ Key Features:
- Tracks model performance over time.
- Automates model deployment.
- Ensures compliance and security.
🔹 Popular MLOps Tools:
| Tool | Purpose |
|---|---|
| TensorFlow Extended (TFX) | End-to-end ML workflow |
| Kubeflow | ML model serving on Kubernetes |
| Amazon SageMaker MLOps | ML lifecycle automation |
💡 Example:
A healthcare AI system monitors its ML model for drift in medical diagnosis accuracy.
🚀 Best Practice: Use model monitoring dashboards to detect accuracy drops in real time.
F. Feature Engineering & Model Development
✅ What is it?
Transforms raw data into ML-ready features.
✅ Key Features:
- Automates feature extraction & selection.
- Supports real-time feature transformations.
- Optimized for training deep learning models.
🔹 Popular Tools:
| Technology | Use Case |
|---|---|
| Feature Store | Centralized feature management |
| AutoML | Automated model training |
| FastAPI | Serving ML models via APIs |
💡 Example:
An autonomous driving system processes camera feed data to extract road conditions & obstacles.
🚀 Best Practice: Standardize feature extraction across ML projects to improve reusability.
4. Challenges in Data Science Infrastructure

Even with cutting-edge tools, data science projects face major challenges.
| Challenge | Solution |
|---|---|
| High compute costs | Use spot instances & auto-scaling clusters. |
| Model reproducibility | Implement data & model versioning. |
| Pipeline failures | Monitor with Airflow & logs. |
| Data privacy issues | Enforce GDPR/HIPAA compliance. |
🚀 Best Practice: Design a modular infrastructure to allow plug-and-play ML components.
5. Final Thoughts
A well-architected data science infrastructure: ✅ Automates data pipelines & ML training.
✅ Supports scalable storage & compute.
✅ Enables continuous monitoring & optimization.
💡 How does your company manage its AI/ML infrastructure? Let’s discuss in the comments! 🚀