comprehensive guide to DataOps: Enhancing Data and Analytics Pipelines for Speed and Efficiency 2024
As data analytics pipelines become more complex, organizations need better collaboration, governance, and automation to handle the increasing volume, velocity, and variety of data. DataOps is an emerging discipline that applies DevOps principles to data engineering, analytics, and machine learning pipelines.
This guide explores: ✅ What is DataOps?
✅ Core principles and foundations of DataOps
✅ How DataOps improves data warehousing, reporting, and data science
✅ Technology framework and tools for DataOps
✅ Benefits and pitfalls of implementing DataOps
1. What is DataOps?

🔹 DataOps (Data Operations) is a set of practices, tools, and frameworks designed to improve the efficiency, agility, and reliability of data and analytics pipelines.
✅ Goals of DataOps:
- Improve collaboration between data engineers, analysts, and business users
- Automate data pipelines for faster time to insights
- Ensure data quality and consistency across all analytics workflows
- Reduce errors and inconsistencies in data processing
- Increase speed and reliability of data analytics
🚀 Example:
A company using manual data processing may take weeks to deliver reports. By implementing DataOps, they can automate data ingestion, transformation, and reporting, reducing cycle times to minutes or hours.
2. DataOps Approach: A New Way to Manage Data Pipelines
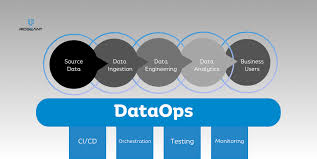
DataOps builds on concepts from software engineering, such as:
✅ Agile methodologies – Rapid iteration and continuous feedback
✅ Lean principles – Minimizing inefficiencies and bottlenecks
✅ CI/CD (Continuous Integration/Continuous Deployment) – Automated testing and deployment
✅ Collaboration tools – Enabling better teamwork across data teams
🔹 Why is DataOps different from traditional data management?
| Traditional Data Processing | DataOps Approach |
|---|---|
| Manual and slow data processing | Automated, real-time data pipelines |
| High chances of errors and inconsistencies | Integrated data validation and testing |
| Siloed teams with poor collaboration | Unified teams using shared tools and processes |
| Long development cycles for data products | Agile, iterative approach for faster results |
🚀 Trend:
DataOps is shifting the focus from just building data pipelines to managing and improving them continuously.
3. Foundations of DataOps
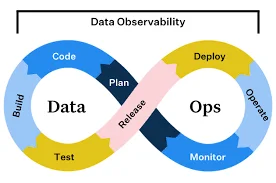
For DataOps to succeed, organizations must adopt a strong foundation that includes people, processes, and technology.
✅ Key Stakeholders in DataOps:
| Role | Responsibilities |
|---|---|
| Data Engineer | Builds and maintains data pipelines |
| Data Scientist | Develops machine learning models |
| BI Analyst | Generates reports and dashboards |
| DataOps Engineer | Ensures automation, testing, and orchestration |
🚀 Best Practice:
Encourage cross-functional collaboration between data engineers, analysts, and business teams.
4. DataOps in Different Data Environments
A. DataOps for Data Warehousing and Data Management
✅ How DataOps improves data warehouses:
- Automates data ingestion from multiple sources
- Ensures schema consistency and data validation
- Uses CI/CD pipelines for automated testing of data updates
💡 Example:
A banking firm automates data validation processes to ensure regulatory compliance before loading data into their Snowflake data warehouse.
🚀 Best Practice:
Use orchestration tools like Apache Airflow or Prefect to manage data workflows efficiently.
B. DataOps for Dashboards and Reports
✅ Challenges in BI reporting:
- Data inconsistency across reports
- Slow refresh times
- Lack of governance
✅ How DataOps helps:
- Standardizes data transformation logic across all reports
- Enables real-time data updates for dashboards
- Improves collaboration between IT and business teams
💡 Example:
A retail company ensures that sales dashboards refresh every hour, avoiding outdated data errors.
🚀 Best Practice:
Use Reverse ETL to sync data warehouse insights back into operational tools (CRM, ERP, Marketing platforms).
C. DataOps for Data Science
✅ Common issues in ML workflows:
- Slow and unreliable feature engineering
- Model drift due to outdated training data
- Lack of pipeline reproducibility
✅ How DataOps helps ML workflows:
- Automates data preparation and model training
- Ensures data consistency between training and production environments
- Uses MLOps frameworks for CI/CD in ML pipelines
💡 Example:
A healthcare startup automates feature extraction for predictive patient diagnostics, reducing model training time by 50%.
🚀 Best Practice:
Use MLflow or Kubeflow to track model versioning and performance metrics.
5. Technology Framework and Tools for DataOps
There are five categories of DataOps tools available today:
| Tool Type | Examples | Use Case |
|---|---|---|
| All-in-One DataOps Tools | DataKitchen, IBM DataOps | Full-stack DataOps solutions |
| Orchestration Tools | Apache Airflow, Prefect | Workflow automation |
| Component Tools | dbt, Great Expectations | Data transformation and validation |
| Case-Specific Tools | Snowflake, BigQuery | Cloud-based data warehousing |
| Open-Source Tools | Apache NiFi, Dagster | Community-driven automation |
🚀 Trend:
Many organizations use a combination of these tools to automate and optimize their DataOps workflows.
6. Benefits of DataOps
✅ Improved Collaboration and Communication
- Encourages a culture of knowledge sharing between teams.
- Reduces departmental silos, leading to faster problem-solving.
✅ Accelerated Time to Production
- Automates data preparation, testing, and deployment.
- Reduces manual effort, enabling faster delivery of insights.
✅ Increased Quality and Reliability
- Uses automated testing and monitoring to detect errors early.
- Improves data governance by enforcing compliance policies.
🚀 Example:
A financial services firm reduced data defects by 80% after implementing automated testing in their DataOps pipeline.
7. Common Pitfalls to Avoid in DataOps
🔹 Overcomplicating the Process:
- DataOps should simplify workflows, not make them more complex.
- Avoid over-engineered solutions that add unnecessary overhead.
🔹 Focusing Too Much on Technology:
- DataOps is not just about tools—it’s about collaboration and process improvement.
- Ensure that business users understand the value of DataOps.
🔹 Lack of Organizational Buy-In:
- Adoption of DataOps requires a shift in culture.
- Train teams and demonstrate business value early.
🚀 Best Practice:
Keep DataOps processes lean and scalable, adapting as the organization grows.
8. Final Thoughts
As data-driven organizations continue to scale, DataOps plays a crucial role in ensuring data quality, automation, and efficiency.
✅ Key Takeaways:
- DataOps accelerates data pipelines for analytics and ML.
- Automation, collaboration, and CI/CD improve pipeline reliability.
- The right mix of tools and frameworks ensures scalability.
- A cultural shift towards DataOps increases efficiency and business value.
💡 How does your company manage DataOps? Let’s discuss in the comments! 🚀