comprehensive guide to Optimizing Deep Learning with Pipeline Parallelism 2024
As AI and machine learning models grow in complexity, training these models efficiently becomes a critical challenge. Deep learning, with its vast networks of interconnected layers, requires massive computational resources and memory. While traditional parallelism techniques like data parallelism and model parallelism are often effective, they can also be limited by hardware constraints. Pipeline parallelism has emerged as a powerful technique to address these challenges, especially for training large models on distributed systems.
In this blog, we will explore the concept of pipeline parallelism, its role in training large AI/ML models, and how it improves both hardware utilization and training efficiency.
What is Pipeline Parallelism?
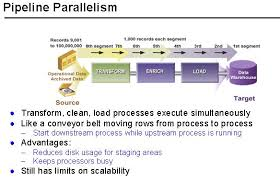
Pipeline parallelism is a technique that divides the model’s layers into multiple stages and pipelines the execution of these stages. Each stage operates on a subset of data, processing it in a sequential manner, while overlapping forward and backward passes. By doing this, we can maximize the use of computational resources, such as GPUs, while minimizing idle times.
Unlike model parallelism, where the model is split across different machines or devices, pipeline parallelism allows each device (or accelerator) to handle a specific portion of the computation for all stages of the model, facilitating the simultaneous processing of different mini-batches.
The Need for Pipeline Parallelism in Modern AI/ML
Training modern AI/ML models, especially large deep learning networks, requires significant computational resources. As models grow in size and complexity, they often cannot fit into the memory of a single machine, leading to the need for distributed training. Traditional parallelization approaches, like data parallelism and model parallelism, have their limitations:
- Data Parallelism: This involves dividing the data into multiple batches and distributing them across several workers. While this improves speed, it still suffers from the challenge of network communication overhead and data bottlenecks.
- Model Parallelism: In model parallelism, large models are divided into segments, with different layers being assigned to different machines or GPUs. However, this can result in significant under-utilization of the computational resources, especially when the model’s layers are interdependent.
Pipeline parallelism aims to solve these problems by overlapping the execution of different stages of the training process, significantly improving both computational efficiency and memory utilization.
How Pipeline Parallelism Works
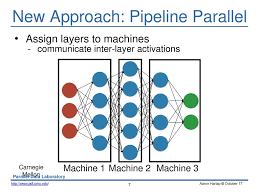
In pipeline parallelism, the model is split into multiple stages, each consisting of a subset of layers. Each stage is mapped to a separate device (such as a GPU), and different batches of data are passed through the stages in a pipeline. The key idea is to allow each device to process different parts of the model and different mini-batches at the same time, while synchronizing at the end of each stage.
The forward pass is pipelined such that one stage processes the first mini-batch while another stage processes the second mini-batch. This allows each device to work continuously on new data, while the backward pass (gradient computation and weight updates) is also pipelined.
This technique significantly reduces idle times and improves the throughput of the system.
Synchronous vs. Asynchronous Pipeline Parallelism

Pipeline parallelism can be implemented in two main ways: synchronous pipeline parallelism and asynchronous pipeline parallelism.
- Synchronous Pipeline Parallelism (GPipe): In synchronous pipeline parallelism, the forward and backward passes are executed in sync across all stages. After each mini-batch is processed through all stages, gradients are synchronized across the devices, and the model is updated. This ensures that the model remains consistent, but it can lead to higher memory consumption due to the need to store activations and gradients for each stage.
- GPipe is a popular implementation of synchronous pipeline parallelism, which splits mini-batches into smaller micro-batches and synchronizes gradients at the end of each pipeline stage. It improves efficiency and can achieve near linear speedup with the number of devices.
- Asynchronous Pipeline Parallelism (PipeDream): In asynchronous pipeline parallelism, different mini-batches are fed into the pipeline without waiting for the completion of the backward pass for the previous mini-batch. After completing the forward pass for a mini-batch, the model parameters are asynchronously updated after the backward pass. This maximizes throughput but can lead to weight staleness (i.e., using outdated weights during training).
- PipeDream is an implementation of asynchronous pipeline parallelism, where mini-batches are continuously injected into the pipeline, and gradient updates occur asynchronously after each mini-batch. PipeDream improves hardware utilization and throughput, but requires additional memory management techniques like weight stashing to mitigate weight staleness.
Challenges in Pipeline Parallelism
While pipeline parallelism significantly improves training efficiency, it comes with its own set of challenges:
- Memory Usage: In synchronous pipeline parallelism, the need to store activations and gradients across stages can lead to high memory consumption. Asynchronous methods like PipeDream use weight stashing to reduce this problem but at the cost of increased memory usage.
- Latency: The effectiveness of pipeline parallelism depends on how well the stages are balanced. If one stage is much slower than the others, it can become a bottleneck, reducing the overall throughput.
- Network Communication: While pipeline parallelism reduces idle times by overlapping the execution of stages, it still requires efficient network communication between devices to pass data (activations, gradients) between stages.
Hybrid Approaches to Improve Performance
In addition to synchronous and asynchronous pipeline parallelism, several hybrid approaches combine data parallelism and pipeline parallelism to achieve even better results:
- DAPPLE (Dynamic Asynchronous Parallel Pipeline) combines the advantages of data and pipeline parallelism by optimizing the memory scheduling to reduce memory consumption and speed up training. It dynamically adapts the scheduling of the backward pass to free memory used for activations.
- PipeMare enhances asynchronous pipeline training by using learning rate rescheduling and discrepancy correction to improve statistical efficiency and achieve better memory usage without staleness.
These hybrid models integrate the best aspects of both data and pipeline parallelism to provide a more efficient training environment, especially for large-scale AI/ML models.
Applications of Pipeline Parallelism
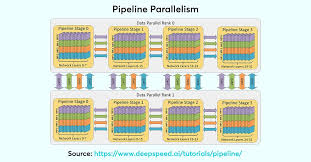
Pipeline parallelism is especially beneficial for large AI/ML models that need to be trained on distributed systems. It has been applied successfully in:
- Natural Language Processing (NLP): Training large transformer models like BERT and GPT.
- Computer Vision: Training deep convolutional networks (CNNs) for tasks like image classification and object detection.
- Speech Recognition: Training large recurrent neural networks (RNNs) for speech-to-text conversion.
Conclusion: The Future of Pipeline Parallelism
Pipeline parallelism is an essential technique for training large, complex models in deep learning. By breaking models into stages and overlapping the execution of mini-batches, pipeline parallelism increases hardware utilization, speeds up training, and reduces memory usage. Whether through synchronous or asynchronous implementations, this approach offers significant performance benefits and is crucial for scaling up AI/ML models on distributed systems.
With ongoing research into memory-efficient solutions and hybrid parallelism, the future of pipeline parallelism promises even better performance, enabling the training of massive models with faster convergence and improved efficiency.