comprehensive guide to Types of Data Architecture: Data Warehouses, Data Lakes, and Data Lakehouses 2024
Data architecture has evolved significantly over the years to accommodate the increasing volume, velocity, and variety of data. The most commonly used architectures include Data Warehouses, Data Lakes, and Data Lakehouses, each serving unique use cases.
This guide explores: ✅ Data Warehouse (DW) and its evolution
✅ Data Lakes and their limitations
✅ The emergence of Data Lakehouse
✅ Comparing Data Warehouse vs. Data Lake vs. Data Lakehouse
1. What is a Data Warehouse?
A Data Warehouse (DW) is a centralized repository used for reporting and analytics. It stores highly structured and formatted data optimized for fast querying.
🔹 Key Characteristics:
- Structured data storage (relational databases, tabular format).
- Optimized for analytics (OLAP workloads).
- Uses ETL (Extract, Transform, Load) processes.
- Time-variant and non-volatile (historical data is preserved).
🔹 Definition by Bill Inmon (Father of Data Warehousing):
“A subject-oriented, integrated, non-volatile, and time-variant collection of data in support of management’s decisions.”
✅ Traditionally used by enterprises with significant budgets but has become more accessible due to cloud-based, pay-as-you-go models.
2. Data Warehouse Architecture
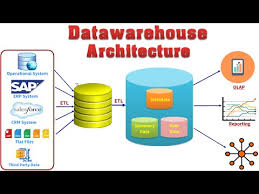
A. Traditional Data Warehouse Model
A Data Warehouse follows a structured ETL process:
1️⃣ Extract: Data is pulled from multiple sources.
2️⃣ Transform: Data is cleaned, standardized, and aggregated.
3️⃣ Load: Processed data is loaded into a Data Warehouse (DW).
💡 Example: A retail company pulls data from point-of-sale systems, inventory databases, and customer transactions to create a centralized reporting system.
B. ELT-Based Data Warehouse
- ELT (Extract, Load, Transform) moves raw data into a staging area before transformation.
- Takes advantage of massive cloud computing power to process data inside the warehouse.
- Used in big data environments (Hadoop, Spark, and cloud data warehouses).
✅ Popular in cloud-based data platforms like Google BigQuery, Amazon Redshift, and Snowflake.
C. Cloud Data Warehouses
Cloud-based Data Warehouses have revolutionized data processing:
| Feature | Benefit |
|---|---|
| Scalability | Can scale up or down on demand. |
| Separation of Compute & Storage | Reduces cost and improves performance. |
| Serverless Processing | No need to manage infrastructure. |
| Limitless Storage | Uses cloud object storage (e.g., Amazon S3, Google Cloud Storage). |
💡 Example: Snowflake and Google BigQuery allow spinning up clusters for specific workloads and deleting them after use, making it cost-efficient.
3. Data Marts: A Subset of Data Warehouse
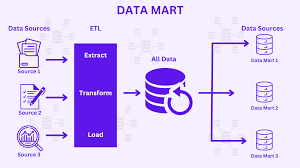
🔹 A Data Mart is a department-specific subset of a Data Warehouse.
🔹 Each department (Marketing, Sales, HR) has its own tailored data views.
🔹 Improves query performance by pre-aggregating data.
✅ Benefits:
- Faster access to department-specific data.
- Reduces query complexity in large datasets.
🚀 Used when different teams need separate, optimized datasets for analytics.
4. What is a Data Lake?

A Data Lake is a centralized storage system that ingests structured, semi-structured, and unstructured data without enforcing schema constraints.
🔹 Key Features:
- Stores raw data in its native format.
- Schema-on-read (data is structured only when queried).
- Massive scalability & cost-efficient (cloud object storage).
- Supports machine learning and big data processing.
💡 Example: A streaming platform like Netflix stores watch history, video logs, and customer interactions in a Data Lake before analyzing it.
A. Challenges of Data Lakes
1️⃣ Data Swamps: Without governance, unstructured data becomes unusable.
2️⃣ Write-Only, Rarely Navigated (WORN) Data: Data that exists but is never used effectively.
3️⃣ Lack of Schema Management: Complex data joins become a nightmare.
🚨 Many organizations struggled to derive real business value from traditional Data Lakes.
5. Data Lakehouse: The Convergence of Data Lakes & Warehouses
The Data Lakehouse is a hybrid architecture that combines the best features of Data Warehouses and Data Lakes.
🔹 Key Features:
- Stores both structured and unstructured data in cloud object storage.
- Supports ACID transactions (Atomicity, Consistency, Isolation, Durability).
- Unifies BI, SQL, and Machine Learning workloads.
- Separates compute from storage for better scalability.
✅ Leading Data Lakehouse Platforms:
- Databricks Delta Lake
- Google BigLake
- Snowflake’s Hybrid Architecture
- AWS Lake Formation
💡 Example: A financial company needs structured reporting (Data Warehouse) and big data analytics (Data Lake). A Data Lakehouse supports both SQL queries and machine learning on the same data.
6. Data Warehouse vs. Data Lake vs. Data Lakehouse
| Feature | Data Warehouse | Data Lake | Data Lakehouse |
|---|---|---|---|
| Data Type | Structured | Structured, Semi-structured, Unstructured | Structured & Unstructured |
| Processing Approach | Schema-on-write | Schema-on-read | Schema-on-write & read |
| Performance | Optimized for BI | High latency for large queries | Optimized for BI & ML |
| Use Cases | Reporting, OLAP | Big data analytics, ML | Hybrid workloads |
| Storage | Expensive | Cost-efficient | Cost-efficient |
🚀 Modern organizations are adopting Data Lakehouses for unified data analytics.
7. The Future of Data Architecture
The lines between Data Warehouses, Data Lakes, and Data Lakehouses are blurring. Organizations are moving towards hybrid architectures that offer: ✅ Unified storage & processing
✅ AI-driven data governance
✅ Flexible, multi-cloud solutions
💡 Vendors like AWS, Azure, and Google Cloud are leading the shift towards integrated Data Platforms.
8. Key Takeaways
✅ Data Warehouses – Best for structured, analytics-ready data.
✅ Data Lakes – Great for storing raw data but require governance.
✅ Data Lakehouses – Best of both worlds, supporting structured and unstructured data.
💡 What type of data architecture is your organization using? Share your thoughts in the comments! 🚀