comprehensive guide to Types of Data Architecture: Exploring Modern Approaches 2024
Data architectures have evolved significantly to address the needs of scalability, real-time processing, and decentralization. Traditional monolithic data warehouses are giving way to modern modular, event-driven, and domain-oriented architectures that improve agility and efficiency.
This blog explores: ✅ Modern Data Stack (MDS)
✅ Lambda and Kappa Architectures
✅ Dataflow Model
✅ Data Mesh Architecture
1. Modern Data Stack (MDS)
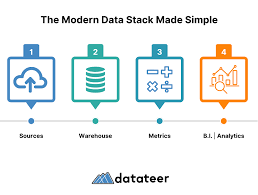
The Modern Data Stack (MDS) is a trending approach that reduces complexity by using modular, cloud-based tools instead of traditional monolithic data architectures.
🔹 Key Features of MDS:
- Cloud-first, plug-and-play solutions
- Easy-to-use, off-the-shelf components
- Highly modular and cost-effective
- Simplifies data pipelines and governance
- Rapidly evolving with new tools
✅ Core Components of MDS:
| Layer | Function | Example Tools |
|---|---|---|
| Data Ingestion | Collects raw data | Fivetran, Airbyte |
| Cloud Storage | Stores data | Amazon S3, Google Cloud Storage |
| Data Transformation | Prepares data for analysis | dbt, Apache Spark |
| Data Management & Governance | Ensures compliance and security | Collibra, Monte Carlo |
| Visualization & Monitoring | BI dashboards & analytics | Looker, Tableau |
🚀 In analytics engineering, MDS is becoming the default choice for data architecture.
2. Lambda Architecture
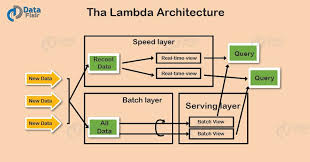
🔹 The Lambda Architecture was developed to handle batch and real-time data processing in a unified system.
🔹 Components of Lambda Architecture: 1️⃣ Batch Layer → Processes historical data at scale
2️⃣ Speed Layer → Provides real-time insights from streaming data
3️⃣ Serving Layer → Aggregates both batch and real-time data
✅ How Lambda Architecture Works:
- The data source is immutable (append-only).
- Data is sent to both the streaming and batch processing layers.
- Streaming data is stored in NoSQL databases for low-latency querying.
- Batch data is processed in a warehouse for precomputed aggregations.
- The serving layer combines both outputs to provide a unified view.
🔹 Example:
A social media analytics platform using Lambda Architecture can:
- Process real-time user interactions in the speed layer.
- Store and aggregate historical post engagement data in the batch layer.
- Serve combined historical + real-time insights through a dashboard.
🚨 Challenges:
Managing separate batch and streaming systems makes Lambda complex and error-prone.
3. Kappa Architecture
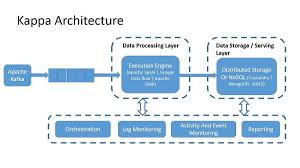
🔹 Kappa Architecture was introduced as an alternative to Lambda to simplify data processing.
✅ Key Idea:
- Instead of using separate batch and stream processing, Kappa processes all data as event streams.
- The same streaming system handles both real-time and batch data.
- Uses event replay to process historical data.
✅ How Kappa Architecture Works:
- Data is ingested as a real-time event stream.
- Streaming analytics frameworks like Apache Kafka, Apache Flink, or Spark Streaming process data on-the-fly.
- Replaying historical events replaces traditional batch processing.
🔹 Example:
An IoT sensor system using Kappa can:
- Process real-time sensor data instantly.
- Replay old sensor logs for analytics without batch processing.
🚀 Benefits:
✅ Simplifies architecture (one system for batch & stream processing).
✅ Supports real-time analytics by default.
🚨 Challenges:
- More expensive and complex than batch processing.
- Not widely adopted yet due to the technical challenges of implementing real-time data streams.
4. Dataflow Model: Unified Batch & Streaming

🔹 Google introduced the Dataflow Model to combine batch and streaming into a single processing system.
✅ Key Idea:
- All data is treated as event streams.
- Batch data is just a bounded stream.
- Real-time data is an unbounded stream.
🔹 Core Features:
- Aggregation happens over event windows (tumbling, sliding windows).
- Unified processing system → One framework for both batch and real-time data.
- Used in Apache Beam, Google Dataflow, Flink, and Spark Streaming.
🚀 Benefits: ✅ Eliminates the need for separate batch & streaming frameworks.
✅ Highly scalable & cloud-native.
✅ More efficient than Kappa & Lambda.
💡 Modern real-time analytics platforms (e.g., Google BigQuery, Snowflake Streaming) are moving towards this model.
5. Data Mesh: Decentralized Data Architecture
🔹 Traditional data platforms (Data Lakes, Warehouses) centralized all data, creating bottlenecks in access, ownership, and governance.
✅ Data Mesh solves this problem by decentralizing data ownership across domains.
🔹 Four Key Principles of Data Mesh (Zhamak Dehghani): 1️⃣ Domain-Oriented Decentralized Data Ownership → Data teams own their own datasets.
2️⃣ Data as a Product → Each dataset is treated as a high-quality product.
3️⃣ Self-Serve Data Infrastructure → Teams have autonomous control over data storage, processing, and security.
4️⃣ Federated Computational Governance → Global policies ensure compliance across teams.
🔹 How Data Mesh Works:
- Instead of a centralized data lake, each business domain (Marketing, Sales, Finance) manages its own data.
- Domains expose their data as APIs or queryable datasets.
- Organizations reduce bottlenecks and enable data democratization.
🚀 Benefits of Data Mesh: ✅ Eliminates bottlenecks in centralized data platforms.
✅ Improves agility & scalability in data-driven enterprises.
✅ Enhances ownership & accountability across business domains.
💡 Companies like Netflix, LinkedIn, and Airbnb are implementing Data Mesh for greater flexibility.
6. Comparing Data Architectures
| Feature | Modern Data Stack | Lambda | Kappa | Dataflow Model | Data Mesh |
|---|---|---|---|---|---|
| Focus | Analytics | Batch & Streaming | Event Streaming | Unified Batch & Stream | Decentralization |
| Complexity | Low | High | Medium | Medium | High |
| Scalability | High | Medium | High | High | High |
| Processing | Batch | Batch & Stream | Streaming | Unified | Distributed |
| Adoption | Growing | Declining | Limited | Increasing | Early Adoption |
🚀 Data Mesh & Dataflow models represent the future of scalable data architectures.
7. Final Thoughts
🔹 The Modern Data Stack is the new standard for analytics.
🔹 Lambda & Kappa solve different challenges but come with complexity trade-offs.
🔹 Dataflow models provide a unified processing approach.
🔹 Data Mesh is the next-generation solution for scaling distributed data teams.
💡 Which data architecture is your organization adopting? Let’s discuss in the comments! 🚀