Data Generation in Source Systems: A Comprehensive Guide 2024
Introduction
Data is the backbone of modern applications, analytics, and machine learning. However, before it can be processed or analyzed, it must be generated, collected, and stored properly. Understanding how data is created, stored, and transmitted across different source systems is crucial for data engineers, developers, and business analysts.
This guide covers: ✅ Types of Data Generation: Analog vs. Digital
✅ Traditional and Modern Source Systems (RDBMS, NoSQL, APIs, and Event-Driven Architectures)
✅ Data Storage, Retrieval, and Querying Mechanisms
✅ Emerging Trends in Data Generation
1. Understanding How Data is Created

Data can be generated in two primary forms:
A. Analog Data Generation
- Occurs in the real world through natural means such as speech, handwriting, and visual signals.
- Often transient (e.g., spoken words) and requires conversion into digital form for storage and analysis.
B. Digital Data Generation
- Native digital data is produced by software applications, sensors, and automated systems.
- Example: A credit card transaction on an e-commerce platform generates structured financial data.
🚀 Example:
A voice recognition system converts analog speech into digital text, making it searchable and analyzable.
2. Traditional Data Source Systems
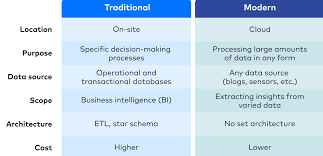
Source systems are responsible for storing, managing, and providing access to data.
A. Relational Databases (RDBMS)
✔ First introduced by IBM in the 1970s and popularized by Oracle.
✔ Uses structured tables to store data in rows and columns.
✔ ACID-compliant (Atomicity, Consistency, Isolation, Durability) ensures data integrity.
✔ Indexes improve search performance using primary and foreign keys.
🚀 Example:
An e-commerce website stores customer orders, payments, and inventory in MySQL or PostgreSQL.
⚠ Challenges:
- Scaling relational databases for high-traffic applications can be complex.
- Normalization prevents data duplication but may reduce query performance.
3. NoSQL Databases: The Modern Alternative
NoSQL databases abandon relational constraints to improve performance, scalability, and flexibility.
A. Key-Value Stores
- Store records as key-value pairs, similar to a dictionary.
- Fast lookups, ideal for caching (e.g., Redis, Amazon DynamoDB).
🚀 Example:
A shopping cart session in an e-commerce app uses Redis to cache user selections.
B. Document Stores
- Store data as JSON objects inside collections.
- Schema-less, allowing for flexible, hierarchical data storage.
- Example: MongoDB, CouchDB.
🚀 Example:
A social media platform stores user profiles, comments, and posts as documents in MongoDB.
⚠ Challenges:
- No built-in joins → Data duplication is common.
- Query performance depends on indexing strategies.
C. Wide-Column Databases
- Store massive amounts of high-velocity data with low latency.
- Example: Apache Cassandra, Google Bigtable.
🚀 Example:
A stock trading application uses Apache Cassandra to store millions of price changes per second.
⚠ Challenges:
- Limited query flexibility (only supports lookups based on primary keys).
- Requires separate analytics systems for complex queries.
D. Search Databases
- Optimized for full-text search and log analytics.
- Example: Elasticsearch, Apache Solr.
🚀 Example:
A customer support chatbot searches a knowledge base using Elasticsearch.
E. Time-Series Databases
- Store data points indexed by time.
- Used for IoT, stock market, and environmental monitoring.
- Example: InfluxDB, TimescaleDB.
🚀 Example:
A weather forecasting model stores real-time temperature readings in TimescaleDB.
4. APIs: The Bridge Between Data Systems

Modern applications exchange data through APIs (Application Programming Interfaces).
A. REST APIs
✔ Most popular API architecture, built on HTTP verbs (GET, POST, PUT, DELETE).
✔ Each call is stateless, meaning no session data is stored between requests.
🚀 Example:
A mobile banking app retrieves account balances via a REST API call.
⚠ Challenges:
- REST APIs return fixed data structures, leading to over-fetching or under-fetching of data.
B. GraphQL APIs
✔ Developed by Facebook, allows fetching multiple data models in a single request.
✔ Flexible queries reduce unnecessary data transfer.
🚀 Example:
A social media app retrieves user profiles, posts, and comments in one request via GraphQL.
C. Event-Driven APIs (Webhooks & Streaming)
✔ Webhooks trigger real-time updates when an event occurs.
✔ Event-streaming platforms continuously stream data to consumers.
✔ Example: Apache Kafka, AWS Kinesis.
🚀 Example:
A fraud detection system processes real-time credit card transactions using Kafka Streams.
5. Cloud Data Sharing and Third-Party Data Sources
✔ Cloud data sharing enables companies to securely exchange data across platforms.
✔ Many companies offer their data as a service via APIs or marketplaces.
🚀 Example:
NASA publishes satellite imagery datasets for scientific research.
⚠ Challenges:
- Data ownership and privacy concerns when sharing across organizations.
6. Message Queues & Event-Streaming Platforms
✔ Used in event-driven architectures to decouple applications and process real-time data.
✔ Message Queues: Deliver small messages asynchronously (e.g., RabbitMQ, Amazon SQS).
✔ Event Streaming: Process large-scale event data (e.g., Apache Kafka, Google Pub/Sub).
🚀 Example:
A ride-sharing app uses Kafka Streams to process real-time location updates.
7. Future Trends in Data Generation
🔹 Serverless Data Processing: Automated, cloud-based data ingestion without infrastructure management.
🔹 Federated Data Processing: Decentralized data pipelines across multiple cloud regions.
🔹 AI-Powered Data Processing: AutoML optimizing data pipelines for faster ETL workflows.
🚀 Prediction:
- GraphQL APIs will become the standard for flexible data access.
- Time-series databases will dominate IoT and financial analytics.
- Hybrid cloud architectures will enhance enterprise data sharing.
8. Conclusion
Understanding data generation in source systems is essential for data engineers, architects, and analysts working with large-scale applications.
✅ Key Takeaways:
- Traditional RDBMS vs. NoSQL: Choose based on performance, scalability, and schema flexibility.
- APIs enable seamless data exchange, with GraphQL emerging as a powerful alternative to REST.
- Event-driven architectures (Kafka, RabbitMQ) are critical for real-time processing.
- Cloud data sharing & AI-driven ETL are the future of enterprise data management.
💡 How does your organization manage data generation? Let’s discuss in the comments! 🚀