Data Pipelines: A Comprehensive Guide to Building Scalable Data Workflows 2024
Data pipelines are essential for moving, transforming, and preparing data for analytics, machine learning (ML), and real-time applications. They automate data movement from sources to destinations, ensuring data consistency, quality, and availability.
This guide covers: ✅ What are data pipelines and why do we need them?
✅ How data pipelines work
✅ Types of data pipelines
✅ Key challenges and best practices
✅ Popular data pipeline tools
1. What is a Data Pipeline?
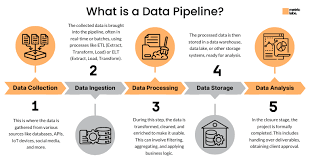
A data pipeline is a series of automated steps that transport data from one system to another, applying transformations and quality checks along the way.
✅ Why do we need data pipelines?
- Automate data flow → Reduces manual data handling.
- Ensure data consistency → Maintains clean, structured data.
- Enable real-time analytics & ML → Supports fast decision-making.
- Improve cloud migration → Moves legacy data to cloud platforms.
🚀 Example Use Cases:
- Marketing teams use data pipelines to track customer behavior.
- Financial institutions detect fraud using real-time data pipelines.
- Healthcare providers monitor patient data for predictive diagnostics.
2. How Data Pipelines Work

Data pipelines involve three main stages:
A. Data Sources
Data originates from various systems, including:
- Databases (Oracle, PostgreSQL, MySQL)
- Streaming sources (Apache Kafka, AWS Kinesis)
- APIs & Web Scrapers
- Cloud storage (Amazon S3, Google Cloud Storage)
✅ Example: An e-commerce company pulls transactional data from MySQL and real-time customer events from Kafka.
B. Data Transformation
Once data is ingested, it undergoes transformation to make it analytics-ready.
✅ Common Transformations:
| Transformation Type | Purpose |
|---|---|
| Data Cleansing | Removes duplicates, corrects missing values |
| Schema Mapping | Converts JSON → Parquet, renames fields |
| Data Aggregation | Computes total sales, customer counts |
| Data Masking | Hides PII (Personally Identifiable Information) |
🚀 Example: A financial services company masks customer credit card details before storing transaction logs.
C. Data Destinations
The processed data is stored in a destination system for analysis and reporting.
✅ Common Data Destinations:
- Data Warehouses (Snowflake, Google BigQuery, Redshift)
- Data Lakes (Azure Data Lake, AWS S3, Hadoop HDFS)
- NoSQL Databases (MongoDB, Cassandra)
- BI & ML Tools (Looker, Tableau, TensorFlow)
🚀 Example: An AI-driven fraud detection system serves processed data to ML models in real-time.
3. Types of Data Pipelines
Data pipelines are categorized based on how they process data.
A. Batch Data Pipelines
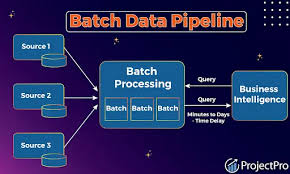
✅ Moves large datasets periodically (hourly, daily, weekly).
✅ Best for historical data analysis, BI reports, and cloud migrations.
💡 Example: A retail company updates daily sales reports in Snowflake.
🚀 Challenge: Delays in reporting due to scheduled processing times.
B. Streaming Data Pipelines
✅ Processes data continuously in real-time.
✅ Used for fraud detection, IoT monitoring, and customer analytics.
💡 Example: A stock trading system processes real-time price updates to detect anomalies.
🚀 Challenge: Requires low-latency infrastructure (Kafka, Flink, Spark Streaming).
C. Change Data Capture (CDC) Pipelines
✅ Tracks changes in a database and syncs them with other systems.
✅ Used for real-time replication, microservices sync, and cloud migrations.
💡 Example: A banking system updates customer balances across multiple databases.
🚀 Challenge: Handling schema drift when table structures change.
4. Challenges in Data Pipelines

Despite their benefits, data pipelines face major challenges.
| Challenge | Solution |
|---|---|
| Schema Drift | Use schema evolution tools (Delta Lake, Iceberg) |
| Data Latency | Optimize with in-memory processing (Apache Flink) |
| Pipeline Failures | Implement monitoring & alerting (Airflow, Datadog) |
| Security & Compliance | Apply encryption & access controls |
🚀 Best Practice: Build resilient pipelines that adapt to schema changes and data quality issues.
5. Popular Data Pipeline Tools
Here are the top tools used for building, managing, and monitoring data pipelines.
A. Data Ingestion Tools
| Tool | Best For |
|---|---|
| Apache Kafka | Event-driven streaming pipelines |
| AWS Glue | Serverless ETL in AWS |
| Fivetran | No-code data pipeline automation |
🚀 Use Case: A logistics company syncs warehouse data with a cloud database using Fivetran.
B. Data Transformation & ETL Tools
| Tool | Best For |
|---|---|
| Apache Spark | Large-scale data transformations |
| dbt (Data Build Tool) | SQL-based transformations |
| Talend | Visual ETL design |
🚀 Use Case: A fintech company converts raw transaction logs into structured financial reports using Apache Spark.
C. Data Pipeline Orchestration
| Tool | Best For |
|---|---|
| Apache Airflow | Workflow scheduling |
| Prefect | Python-native orchestration |
| Dagster | ML & ETL pipeline management |
🚀 Use Case: A healthcare company automates data pipeline failures and retries using Apache Airflow.
6. Best Practices for Data Pipelines
✅ Choose the right pipeline type: Use batch for reporting and streaming for real-time insights.
✅ Monitor pipeline health: Use logging & alerting tools to detect failures early.
✅ Optimize for performance: Use columnar storage formats (Parquet, ORC) for faster queries.
✅ Secure sensitive data: Apply data masking and encryption to protect PII.
✅ Enable scalability: Use serverless architectures (AWS Glue, Google Dataflow) to handle spikes in data loads.
🚀 Future Trend: AI-powered smart pipelines will automate error detection & data quality checks.
7. Final Thoughts
Data pipelines power modern data-driven organizations by automating data flow, transformation, and analytics. Whether it’s batch, streaming, or CDC pipelines, the key is to build resilient, scalable, and cost-efficient systems.
✅ Key Takeaways:
- Batch pipelines handle scheduled data processing.
- Streaming pipelines enable real-time analytics.
- CDC pipelines ensure real-time data synchronization.
- Data pipeline tools help automate and monitor workflows.
💡 What data pipeline tools does your company use? Let’s discuss in the comments! 🚀