Data Pipelines vs. Machine Learning Pipelines: Key Differences, Architectures, and Best Practices 2024
In the world of data engineering and artificial intelligence (AI), pipelines are essential to handling large-scale data processing, automation, and machine learning (ML) model deployment. However, data pipelines and ML pipelines serve different purposes and require unique architectures, tools, and best practices.
This comprehensive guide explores: ✅ What are Data Pipelines and ML Pipelines?
✅ Architectural differences between the two
✅ Best practices for designing scalable pipelines
✅ Challenges and real-world use cases
✅ Future trends in Data and ML pipelines
1. What is a Data Pipeline?
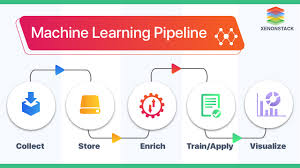
A data pipeline is a structured process that extracts, transforms, and loads (ETL) data from multiple sources into storage or analytics systems.
Key Functions of a Data Pipeline
✅ Data Ingestion – Collecting structured and unstructured data from APIs, databases, event logs, IoT devices, and real-time streams.
✅ Data Processing – Cleaning, normalizing, and aggregating data for analytical insights.
✅ Data Storage – Saving processed data into data lakes, data warehouses, or cloud storage.
✅ Data Delivery – Making data available for BI tools, dashboards, and applications.
🚀 Example:
A financial institution collects credit card transactions, cleans and structures the data, and sends it to a fraud detection dashboard for real-time alerts.
2. What is a Machine Learning Pipeline?
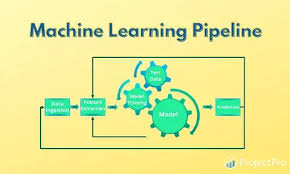
An ML pipeline automates the steps involved in training, evaluating, and deploying ML models.
Key Functions of an ML Pipeline
✅ Feature Engineering – Creating useful input variables from raw data.
✅ Model Training & Evaluation – Using supervised, unsupervised, or reinforcement learning techniques.
✅ Hyperparameter Tuning – Optimizing ML model parameters for better accuracy.
✅ Model Deployment & Inference – Serving ML models via APIs or cloud services.
✅ Model Monitoring – Tracking model performance to detect drift and retrain when needed.
🚀 Example:
An e-commerce platform builds a product recommendation system that continuously trains models on customer behavior data and automatically updates recommendations.
3. Data Pipeline vs. ML Pipeline: Key Differences
| Aspect | Data Pipeline | ML Pipeline |
|---|---|---|
| Primary Goal | Moves and processes raw data for analytics | Automates the ML lifecycle |
| Main Components | ETL (Extract, Transform, Load) | Data Preprocessing, Model Training, Deployment |
| Data Flow | One-directional (source → storage) | Cyclical (model retraining with new data) |
| Processing Type | Batch, real-time (ETL, streaming) | Iterative (training, tuning, inference) |
| End Users | Data analysts, engineers | Data scientists, ML engineers |
| Common Tools | Apache Airflow, Kafka, Snowflake | TensorFlow, PyTorch, Kubeflow |
🚀 Key Takeaway:
- Data Pipelines handle raw data ingestion and processing.
- ML Pipelines focus on model training, deployment, and continuous learning.
4. How Data Pipelines and ML Pipelines Work Together
While data pipelines and ML pipelines serve different purposes, they often work in tandem within a modern AI-driven architecture.
Example Workflow
1️⃣ Data Pipeline: Collects customer interaction logs from an e-commerce website.
2️⃣ Data Cleaning: Removes duplicates, missing values, and erroneous records.
3️⃣ ML Pipeline: Uses processed data to train a recommendation model.
4️⃣ Deployment: The trained model serves personalized product recommendations.
5️⃣ Continuous Learning: New user interactions improve the model over time.
🚀 Use Case: A healthcare system ingests patient records (Data Pipeline), trains AI models for diagnostics (ML Pipeline), and deploys predictive analytics for doctors.
5. Architecture of Data and ML Pipelines
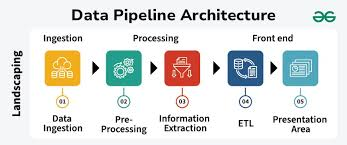
Both data pipelines and ML pipelines require robust architectures to ensure scalability, reliability, and automation.
A. Data Pipeline Architecture
✅ Data Sources: APIs, relational databases, streaming platforms (Kafka, Flink).
✅ ETL Processing: Batch (Apache Spark) or streaming (Apache Flink, AWS Kinesis).
✅ Data Storage: Data warehouses (Snowflake, BigQuery), data lakes (S3, Delta Lake).
✅ Data Serving: BI dashboards, data marts, or analytical models.
🚀 Example: A bank collects transaction logs → stores them in AWS S3 → loads structured data into Snowflake → enables real-time fraud analytics.
B. ML Pipeline Architecture
✅ Feature Store: Centralized repository for engineered features (Feast, Tecton).
✅ Model Training: AutoML or custom ML frameworks (TensorFlow, PyTorch).
✅ Hyperparameter Tuning: Optimize model performance (Optuna, Ray Tune).
✅ Model Serving: Deploy using TensorFlow Serving, Kubernetes, AWS SageMaker.
✅ Monitoring & Feedback Loop: Detect model drift and trigger retraining.
🚀 Example: A chatbot ingests customer queries, improves NLP models, and deploys updated models without service downtime.
6. Best Practices for Data Pipelines
✅ Modular Design: Break ETL processes into independent, reusable components.
✅ Real-Time Processing: Use Apache Kafka for streaming ingestion.
✅ Automate Data Quality Checks: Implement Great Expectations for validation.
✅ Scalable Storage: Store large datasets in cloud-based data lakes.
✅ Monitor Performance: Use Airflow DAGs for error detection.
🚀 Trend: Serverless data pipelines are reducing maintenance overhead.
7. Best Practices for ML Pipelines
✅ Automate Model Retraining: Set up scheduled model retraining jobs.
✅ Use Feature Stores: Centralized feature management ensures consistency.
✅ Optimize Hyperparameters: Automate tuning for best performance.
✅ Deploy in Containers: Use Docker + Kubernetes for scalability.
✅ Monitor Model Drift: Track prediction accuracy in production.
🚀 Trend: MLOps (Machine Learning Operations) is enabling self-healing AI systems.
8. Challenges in Data & ML Pipelines
| Challenge | Solution |
|---|---|
| Data Silos | Implement a unified data lake architecture |
| Pipeline Failures | Use workflow orchestration tools (Apache Airflow) |
| Model Drift | Set up automated monitoring and retraining |
| High Latency | Optimize queries with distributed computing |
| Compliance & Security | Encrypt sensitive data and apply role-based access control |
🚀 Example: A fintech company encrypts transaction logs to meet GDPR compliance.
9. Future Trends in Data & ML Pipelines
🔹 AI-Powered Data Pipelines: Automating data quality checks and ETL workflows.
🔹 Federated Learning Pipelines: Training ML models across decentralized devices without sharing raw data.
🔹 Data Mesh Architecture: Enabling decentralized data ownership while maintaining interoperability.
🔹 Hybrid Cloud Pipelines: Combining on-prem and cloud storage solutions.
🔹 Edge AI Pipelines: Running ML models directly on IoT devices for real-time inference.
🚀 Prediction:
- AI-driven AutoML pipelines will require minimal human intervention.
- Real-time ML pipelines will power next-gen personalization and fraud detection.
10. Final Thoughts
Both data pipelines and ML pipelines are essential for modern AI-driven businesses. While they serve different purposes, their integration ensures high-quality data, automated ML workflows, and scalable AI applications.
✅ Key Takeaways:
- Data Pipelines prepare structured data for analysis.
- ML Pipelines focus on automated model training and deployment.
- Combining both pipelines enables end-to-end AI workflows.
💡 How does your company handle Data & ML pipelines? Let’s discuss in the comments! 🚀