Federated Learning: A Decentralized Approach to Secure and Efficient Machine Learning 2024

With the growing importance of data privacy, distributed computing, and the rise of edge devices, Federated Learning (FL) has emerged as a critical technique to enhance machine learning (ML) while addressing privacy concerns. This blog explores Federated Learning from the ground up, its core components, use cases, and the frameworks that are shaping its practical application.
What is Federated Learning?

Federated Learning (FL) is a distributed machine learning approach that allows model training on decentralized data without transferring it to a central server. This decentralization improves data privacy and reduces communication costs associated with traditional cloud-based machine learning approaches.
Unlike centralized machine learning models where data is collected in one place for training, FL keeps the data on local devices or machines, only sharing model updates. This ensures that sensitive data like personal information or proprietary business data never leaves the device or system that generated it.
Why Federated Learning Matters
Federated Learning was conceived to address several critical challenges in machine learning:
- Data Privacy: In traditional centralized machine learning, data is transferred to a central server for processing, which opens the door for data breaches. In Federated Learning, since the data never leaves the device, privacy is preserved.
- Communication Costs and Latency: Transferring massive amounts of data to central servers for training is inefficient and time-consuming. FL reduces this overhead by only sharing model updates, which are smaller than raw data.
- Data Access: In many cases, data is distributed across multiple organizations or devices, making it difficult to share. Federated Learning enables collaborative model training without data sharing.
How Does Federated Learning Work?

The Federated Learning process involves two primary phases:
- Model Training Phase: Each client (or data owner) trains a local model using its data. Instead of sharing raw data, each client sends only model updates (weights and gradients) to a central server.
- Model Aggregation Phase: The central server aggregates the updates from all clients to create a global model, which is then shared back with the clients for further training.
The process is iterative and can run synchronously or asynchronously, depending on the scenario.
Federated Learning Architectures
There are two primary architectures in Federated Learning:
- Client-Server Architecture: This is the most common architecture where a central server coordinates the model aggregation. Each client trains its model and sends updates to the server. While simple, it requires a trusted server, which can be a vulnerability point for attacks.
- Peer-to-Peer Architecture: In this architecture, there is no central server. Clients interact directly with one another to share model updates. This is more secure but can increase communication costs and complexity.
Types of Federated Learning
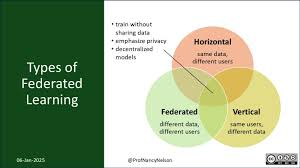
Federated Learning is categorized into three types based on the data distribution:
- Horizontal Federated Learning (HFL): In this case, data is partitioned by samples. Each client owns different subsets of the same feature space. For example, mobile phones collecting data from different users can perform HFL.
- Vertical Federated Learning (VFL): Here, data is partitioned by features. Clients may own the same samples but different features. For example, different hospitals may have the same set of patients but different medical records.
- Federated Transfer Learning (FTL): This type applies when data from different sources has no overlap in features or samples. It’s useful when knowledge is transferred from one domain to another without a shared feature space.
Use Cases for Federated Learning
Federated Learning has found applications in several fields due to its ability to train models on decentralized data while ensuring privacy:
- Healthcare: FL can be used for medical image classification or disease prediction while ensuring that medical data from patients remains private across hospitals.
- IoT: Devices like smart thermostats or wearables generate vast amounts of data. FL enables these devices to improve their models without transferring sensitive data to central servers.
- Banking and Finance: FL is useful in fraud detection systems, where banks can collaboratively train models using data from multiple institutions without sharing sensitive customer information.
Federated Learning Frameworks
Several open-source frameworks have been developed to support Federated Learning. These frameworks simplify the deployment of federated learning models and include:
- TensorFlow Federated (TFF): A popular framework that extends TensorFlow to support federated learning. It allows the development and evaluation of machine learning models across decentralized data sources.
- Flower: An easy-to-use framework for federated learning that allows the integration of TensorFlow, PyTorch, and other ML libraries.
- PySyft: A library that extends PyTorch for privacy-preserving machine learning, including support for federated learning.
- FATE (Federated AI Technology Enabler): A comprehensive federated learning framework designed to support both horizontal and vertical federated learning scenarios.
- IBM Federated Learning: A framework by IBM that supports federated learning in AI applications with an emphasis on secure and privacy-preserving technologies.
Challenges in Federated Learning
While Federated Learning presents numerous benefits, there are several challenges:
- Data Heterogeneity: Data from different clients may follow different distributions, leading to difficulties in model convergence, especially in non-IID (non-independent and identically distributed) data.
- Communication Efficiency: The communication between clients and the server can be costly, particularly in scenarios with a large number of clients or frequent updates.
- Security: FL models are vulnerable to attacks like data poisoning or model inversion, where attackers try to extract sensitive data from model updates.
- Personalization: While FL aims to create a global model, it often fails to accommodate the specific needs of individual clients, which could lead to reduced performance for clients with unique data distributions.
Federated Learning Trends
Federated Learning is evolving rapidly, and several trends are shaping its future:
- Adversarial Attacks and Defenses: As FL models become more widely adopted, researchers are focusing on defending against attacks like model poisoning or privacy leakage through robust aggregation and anomaly detection mechanisms.
- Personalized Federated Learning (PFL): As traditional FL models may fail to meet the specific needs of clients with unique data distributions, personalized federated learning is gaining traction to tailor models for individual clients.
- Federated Transfer Learning: This emerging trend is enabling knowledge transfer across domains where data distributions don’t overlap, making it useful in fields like healthcare or finance.
Conclusion: The Future of Federated Learning
Federated Learning represents a breakthrough in the way we handle privacy-sensitive data for machine learning. By decentralizing model training and maintaining data privacy, FL enables machine learning models to be trained across multiple devices and organizations without data sharing.
Despite its challenges, such as data heterogeneity and communication costs, FL has the potential to revolutionize industries like healthcare, finance, and IoT. With the continued development of frameworks and the integration of security measures, Federated Learning will play a key role in shaping the future of machine learning.