Machine Learning Pipelines: A Complete comprehensive Guide to Model Engineering and Deployment 2024
Introduction
Machine Learning (ML) Pipelines are a structured and automated way to train, evaluate, and deploy ML models efficiently. They ensure that machine learning workflows are scalable, reproducible, and maintainable.
In this guide, we will cover: ✅ What is a Machine Learning Pipeline?
✅ Key Stages of ML Pipelines
✅ Model Engineering & Deployment Best Practices
✅ Serialization Formats for ML Models
1. What is a Machine Learning Pipeline?

An ML pipeline orchestrates the entire workflow of an ML project, from data preprocessing to model training and deployment. The goal is to automate repetitive tasks and allow ML models to be seamlessly integrated into real-world applications.
Benefits of ML Pipelines
✔ Automation: Reduces manual effort in training and deployment.
✔ Scalability: Allows handling of large datasets and complex models.
✔ Reproducibility: Ensures models can be retrained and tested consistently.
✔ Monitoring & Updates: Supports continuous improvements and retraining.
🚀 Example:
A financial institution deploys an ML pipeline for fraud detection. The pipeline continuously trains new models on incoming transactions and deploys updates in real time.
2. Key Stages in a Machine Learning Pipeline
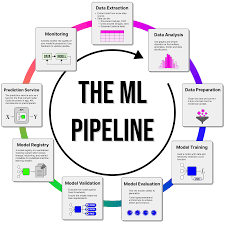
An ML pipeline consists of multiple stages, ensuring smooth model development, evaluation, and deployment.
| Stage | Purpose |
|---|---|
| Feature Engineering | Transform raw data into meaningful input variables |
| Model Training | Apply ML algorithms to learn patterns in data |
| Hyperparameter Tuning | Optimize model parameters to improve performance |
| Model Evaluation | Validate model accuracy using test datasets |
| Model Testing | Ensure model generalization using unseen data |
| Model Packaging | Convert models into a deployable format |
🚀 Example:
An e-commerce website uses an ML pipeline to recommend products based on user interactions. The model is continuously updated to improve accuracy.
3. Feature Engineering in ML Pipelines
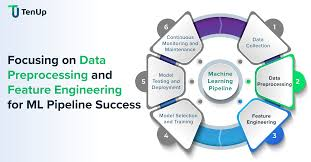
Feature Engineering involves creating new variables from raw data to improve ML performance.
Common Feature Engineering Techniques
✔ Discretizing Continuous Features – Convert numerical data into categorical bins.
✔ Feature Decomposition – Split dates, text, and categories into meaningful sub-features.
✔ Feature Transformation – Apply logarithm, square root, or power transformations.
✔ Feature Scaling – Normalize or standardize data for better model convergence.
✔ Feature Aggregation – Create meaningful aggregate metrics.
🚀 Example:
A stock market prediction model aggregates trading volumes from multiple exchanges to improve forecasts.
4. Model Training and Hyperparameter Tuning
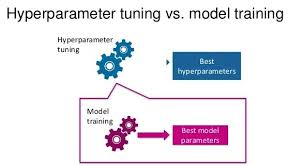
Model training is the process of applying ML algorithms on data to create a predictive model.
Model Training Workflow
✔ Use different ML algorithms (Logistic Regression, Random Forest, SVM, etc.).
✔ Perform Cross-validation – Use N-fold validation to reduce variance.
✔ Error Analysis – Identify and address incorrect predictions.
✔ Hyperparameter Tuning – Optimize learning rate, number of trees, layers, etc.
Popular Hyperparameter Tuning Techniques
| Method | Best For |
|---|---|
| Grid Search | Small-scale parameter tuning |
| Random Search | Faster alternative to grid search |
| Bayesian Optimization | AI-driven tuning of ML models |
| Genetic Algorithms | Evolves model hyperparameters over iterations |
🚀 Example:
A medical diagnosis AI system fine-tunes hyperparameters of deep learning models to improve accuracy in disease detection.
5. Model Evaluation and Testing
Before deploying, an ML model must be evaluated for accuracy, robustness, and fairness.
Key Model Evaluation Metrics
| Metric | Use Case |
|---|---|
| Accuracy | General classification models |
| Precision & Recall | Imbalanced datasets (e.g., fraud detection) |
| F1 Score | Harmonic mean of precision & recall |
| ROC-AUC | Binary classification performance |
| RMSE / MAE | Regression model evaluation |
🚀 Example:
A customer sentiment analysis model is tested using real-world social media comments before deployment.
6. Model Packaging and Serialization
Once an ML model is trained and validated, it must be packaged for deployment.
What is ML Model Serialization?
Serialization converts trained ML models into a format that can be stored, transferred, and deployed in production systems.
Common ML Model Serialization Formats
| Format | Description | Supported Frameworks |
|---|---|---|
| PMML | XML-based format for model exchange | Scikit-Learn, XGBoost |
| PFA | JSON-based executable model representation | Open-source ML tools |
| ONNX | Open standard format for deep learning | TensorFlow, PyTorch |
| .pkl (Pickle) | Python object serialization format | Scikit-learn |
| H2O MOJO/POJO | Java-compatible model format | H2O.ai |
| .h5 (HDF5) | Hierarchical Data Format for deep learning models | Keras, TensorFlow |
| CoreML (.mlmodel) | Apple’s ML model format for iOS apps | CoreML, TensorFlow |
🚀 Example:
A computer vision AI model is converted to ONNX format so it can run on multiple platforms, including mobile and cloud services.
7. Model Deployment and Inference
ML models need to be deployed as APIs or embedded into applications, cloud platforms, or edge devices.
Deployment Strategies
✔ Batch Processing – Deploy models for offline predictions.
✔ Real-time Inference – Serve ML models via APIs.
✔ A/B Testing – Compare new models against previous versions.
✔ Canary Deployment – Release new models to a small user group first.
Popular Model Deployment Tools
| Tool | Use Case |
|---|---|
| TensorFlow Serving | Real-time deep learning inference |
| TorchServe | PyTorch-based model deployment |
| FastAPI & Flask | API-based ML model serving |
| AWS SageMaker | Cloud-based ML model hosting |
| Kubernetes + Docker | Scalable ML model deployment |
🚀 Example:
A financial firm deploys a risk assessment model using AWS Lambda for real-time loan approvals.
8. Monitoring and Updating ML Pipelines
After deployment, ML models must be continuously monitored for performance degradation.
Key Aspects of Model Monitoring
✔ Detect Model Drift – Identify changes in input data distribution.
✔ Monitor Prediction Quality – Check if the model’s accuracy decreases.
✔ Retraining Triggers – Schedule automatic retraining when drift is detected.
Popular Monitoring Tools
| Tool | Use Case |
|---|---|
| EvidentlyAI | Drift detection for ML models |
| MLflow | Model tracking and experiment logging |
| Prometheus + Grafana | Real-time monitoring & alerting |
🚀 Example:
A self-driving car AI pipeline monitors road conditions and retrains models when new traffic patterns emerge.
9. Conclusion: Why ML Pipelines Matter
ML Pipelines automate, streamline, and optimize machine learning workflows, making AI applications scalable, efficient, and production-ready.
✅ Key Takeaways:
- ML Pipelines automate data preparation, training, evaluation, and deployment.
- Feature Engineering & Hyperparameter Tuning improve model performance.
- Serialization Formats allow seamless model portability.
- Monitoring ensures ML models stay accurate and up-to-date.
💡 How do you manage ML pipelines in your projects? Let’s discuss in the comments! 🚀