The Modern Data Stack: A Comprehensive Guide to Scalable Data Infrastructure 2024
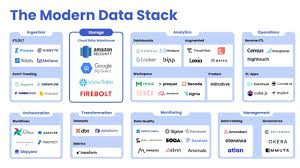
The Modern Data Stack (MDS) is a cloud-native, flexible, and scalable approach to handling data in organizations. It leverages best-of-breed tools for data ingestion, storage, transformation, and analytics to enable faster insights and better decision-making.
This guide explores: ✅ Traditional Data Stack (TDS) vs. Modern Data Stack (MDS)
✅ Key building blocks of a Modern Data Platform
✅ Popular tools for ingestion, storage, transformation, and analytics
✅ Challenges and best practices for implementing MDS
1. Why Migrate from Traditional Data Stacks (TDS) to Modern Data Stacks (MDS)?
🔹 Traditional Data Stack (TDS) Challenges:
- High infrastructure costs (on-premise servers, maintenance, IT support).
- Slow ETL (Extract, Transform, Load) processes, delaying data availability.
- Long turnaround time for data engineers and analysts to set up reports.
- Limited scalability, making it difficult to accommodate business growth.
🚀 Example:
A company using an on-premise database faces weeks of delay in generating reports due to manual data processing and complex system dependencies.
✅ Modern Data Stack (MDS) Benefits:
- Cloud-based infrastructure reduces maintenance costs.
- Fast ELT (Extract, Load, Transform) enables real-time insights.
- Pay-as-you-go pricing models ensure cost efficiency.
- Plug-and-play integrations with best-in-class tools.
🚀 Trend: Organizations are moving from monolithic on-premise data solutions to cloud-based, modular architectures.
2. Key Building Blocks of a Modern Data Platform

An MDS consists of multiple components, each handling different aspects of data processing.
A. Data Ingestion: Bringing Data from Multiple Sources
✅ What It Does:
- Collects data from APIs, databases, event streams, and applications.
- Uses batch (ETL) and real-time (streaming) pipelines to load data efficiently.
🔹 Popular Data Ingestion Tools:
| Tool Type | Examples |
|---|---|
| SaaS ETL Tools | Fivetran, Hevo Data, Stitch |
| Open-Source Tools | Singer, StreamSets |
| Streaming Pipelines | Apache Kafka, Confluent, Google Pub/Sub |
🚀 Trend: Streaming-first architectures are replacing batch processing for faster insights.
B. Data Storage and Processing: Warehouses, Lakes, and Lakehouses
✅ What It Does:
- Stores raw, semi-structured, and structured data.
- Ensures fast access for analytics and ML models.
🔹 Three Types of Data Storage in MDS:
| Storage Type | Description | Popular Tools |
|---|---|---|
| Data Warehouses | Optimized for structured analytics | Snowflake, Google BigQuery, Redshift |
| Data Lakes | Stores raw, unstructured data | Amazon S3, Azure Data Lake, Google Cloud Storage |
| Data Lakehouses | Hybrid of warehouses & lakes | Databricks, Delta Lake |
🚀 Trend: Data lakehouses combine cost-efficiency of lakes with query performance of warehouses.
C. Data Transformation: Making Data Analytics-Ready
✅ What It Does:
- Cleans, enriches, and models data for analytics and ML.
- Applies business logic, aggregations, and feature engineering.
🔹 Popular Data Transformation Tools:
| Tool Type | Examples |
|---|---|
| SQL-Based | dbt, Matillion |
| Python-Based | Apache Airflow, Pandas, Spark |
🚀 Best Practice: Use dbt for SQL transformations and Airflow for orchestrating workflows.
D. Business Intelligence & Data Analytics
✅ What It Does:
- Provides self-service analytics and reporting.
- Enables real-time dashboards for business insights.
🔹 Popular BI & Analytics Tools:
| Tool | Use Case |
|---|---|
| Looker, Mode | Self-service analytics |
| Tableau, Power BI | Interactive dashboards |
| Redash, Superset | Open-source visualization |
🚀 Trend: Modern BI tools are shifting from static reports to interactive, real-time data exploration.
E. Data Governance, Privacy, and Security
✅ What It Does:
- Ensures data integrity, compliance, and access control.
- Manages data lineage, cataloging, and security policies.
🔹 Popular Data Governance Tools:
| Tool Type | Examples |
|---|---|
| Data Cataloging | Atlan, Apache Atlas, DataHub |
| Access Governance | Immuta, Privacera, Apache Ranger |
🚀 Trend: Organizations are adopting centralized data governance frameworks to comply with GDPR, HIPAA, and SOC2.
3. Other Important Components of a Modern Data Stack
| Category | Popular Tools |
|---|---|
| Real-Time Processing | Apache Flink, Apache Spark Streaming |
| Data Science & ML | Jupyter Notebooks, DataRobot, AWS SageMaker |
| Event Collection | Segment, Snowplow |
| Data Quality & Testing | Great Expectations, Deequ |
🚀 Trend: Companies are moving beyond BI to AI-powered analytics and real-time event processing.
4. Challenges of Implementing a Modern Data Stack
| Challenge | Solution |
|---|---|
| Tool Overload | Choose best-of-breed tools with seamless integrations |
| Data Silos | Implement data lakehouses for unified access |
| Cost Management | Use pay-as-you-go cloud models to optimize spending |
| Governance Issues | Apply automated compliance and security policies |
🚀 Best Practice: Start small, evaluate your needs, and scale gradually.
5. Future Trends in Modern Data Stacks
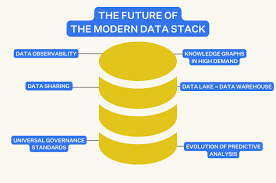
🔹 What’s next for MDS?
- Automated DataOps workflows for reducing manual effort.
- AI-powered data transformations to generate insights faster.
- Serverless and No-Code Data Platforms making analytics accessible to non-tech users.
- Multi-Cloud and Hybrid Data Strategies for flexibility and resilience.
🚀 Prediction: The future of MDS will be autonomous, AI-driven, and more self-service-friendly.
6. Final Thoughts
The Modern Data Stack (MDS) is transforming how businesses handle data, making insights more accessible, faster, and cost-efficient.
✅ Key Takeaways:
- MDS replaces traditional, slow data architectures with scalable cloud solutions.
- Data warehouses, lakes, and lakehouses provide flexibility for different use cases.
- Automation in ingestion, transformation, and analytics improves efficiency.
- Governance and security must be prioritized for compliance.
💡 Is your organization adopting a Modern Data Stack? Share your thoughts in the comments! 🚀